Entfesseln Sie die Magie von GenAI: So passen Sie Foundation-Modelle mit benutzerdefinierten Daten an

Haben Sie sich schon einmal gefragt, ob und wie Sie moderne Basismodelle mit Ihren eigenen Daten verwenden können, ohne Infrastruktur?
In diesem Beitrag erkunden wir die spannenden Möglichkeiten der Anpassung von Basismodellen, um maßgeschneiderte Lösungen für Ihre spezifische Domäne, Organisation zu erstellen, und Anwendungsfall, durch Nutzung der Leistungsfähigkeit von Amazon Bedrock und Mendix.
Amazon Bedrock und die Kammer der benutzerdefinierten Daten
Kurz und letzten Blogerklärten wir, wie einfach es ist, intelligente und intuitive Apps zu erstellen mit Amazon Bedrock, ein vollständig verwalteter Dienst, der leistungsstarke Basismodelle (FMs) von führenden KI-Startups und Amazon zur Verfügung stellt.
Ab März 2024 umfasst Amazon Bedrock die folgenden Basismodelle:
- Amazonas-Titan
- Anthropischer Claude
- Cohere-Befehle und -Einbettung
- AI21 Labs Jurassic
- Meta Lama 2
- Mistral-KI
- Stabilität AI Stabile Diffusion XL
Die Liste wird regelmäßig mit neuen und verbesserten Modellen aktualisiert.
Neben den Basismodellen hat AWS Amazon Bedrock mit zusätzlichen Konzepten als Teil der Bedrock-Toolbox erweitert..'. Die neueste Funktionalität ermöglicht die Verwendung benutzerdefinierter Daten mit Basismodellen mithilfe von Wissensdatenbanken und Agenten.
Natürlich Mendix möchte unsere Amazon Bedrock Connector Bleiben Sie auf dem neuesten Stand mit allen aktuellen Funktionen und nutzen Sie die neuen Amazon Bedrock-Funktionen. Aus diesem Grund haben wir eine Version 2.3.0 des Connectors veröffentlicht, die mehrere neue Vorgänge und Beispiele im Zusammenhang mit Wissensdatenbanken und Agenten enthält.
Der Mendix Amazon Bedrock Connector und die Reihenfolge neuer Vorgänge
In den folgenden Abschnitten demonstrieren wir verschiedene Ansätze zum Anpassen von FMs mit benutzerdefinierten Daten.
Zunächst besprechen wir Retrieval Augmented Generation (RAG), eine Technik, die Daten aus verschiedenen Datenquellen abruft und die Eingabeaufforderung erweitert, um mithilfe von Wissensdatenbanken relevantere und genauere Antworten bereitzustellen. Wir zeigen, wie eine solche Amazon Bedrock-Wissensdatenbank mit den FMs verwendet wird, sowohl mit als auch ohne Amazon Bedrock-Agenten.
Als nächstes folgt eine Einführung in das Prompt Engineering. Beim Prompt Engineering geht es darum, qualitativ hochwertige Eingabeaufforderungen zu erstellen, die generative KI-Modelle um sinnvolle und kohärente Antworten zu produzieren. Sie werden sehen, wie es in Ihrem Mendix Anwendung.
So richten Sie eine Wissensdatenbank ein und verwenden sie
In einer Wissensdatenbank dreht sich alles um Daten. Wir zeigen Ihnen, wie Sie die neuen Daten in eine Datenquelle einspeisen und wie Sie ein Einbettungsmodell und eine Zielvektordatenbank verwenden.
Wenn Sie den Vorgang mitverfolgen möchten, stellen Sie sicher, dass Sie Zugriff auf Folgendes haben:
- Die Amazon-Konsole
- Amazon Bedrock (ab März 2024 sind Wissensdatenbanken und Agenten in den Regionen us-east-1 und us-west-2 verfügbar)
- Amazon S3
Stellen Sie sicher, dass Sie auch Datendateien zu S3 hinzufügen. Die folgenden Formate werden unterstützt:
- Nur-Text (.txt)
- Abschlag (.md)
- HyperText Markup Language (.html)
- Microsoft Word-Dokument (.doc/.docx)
- Durch Kommas getrennte Werte (.csv)
- Microsoft Excel-Tabelle (.xls/.xlsx)
- Portables Dokumentenformat (.pdf)
- Einloggen, um AWS-Konsole und navigieren Sie zu Amazon Bedrock.
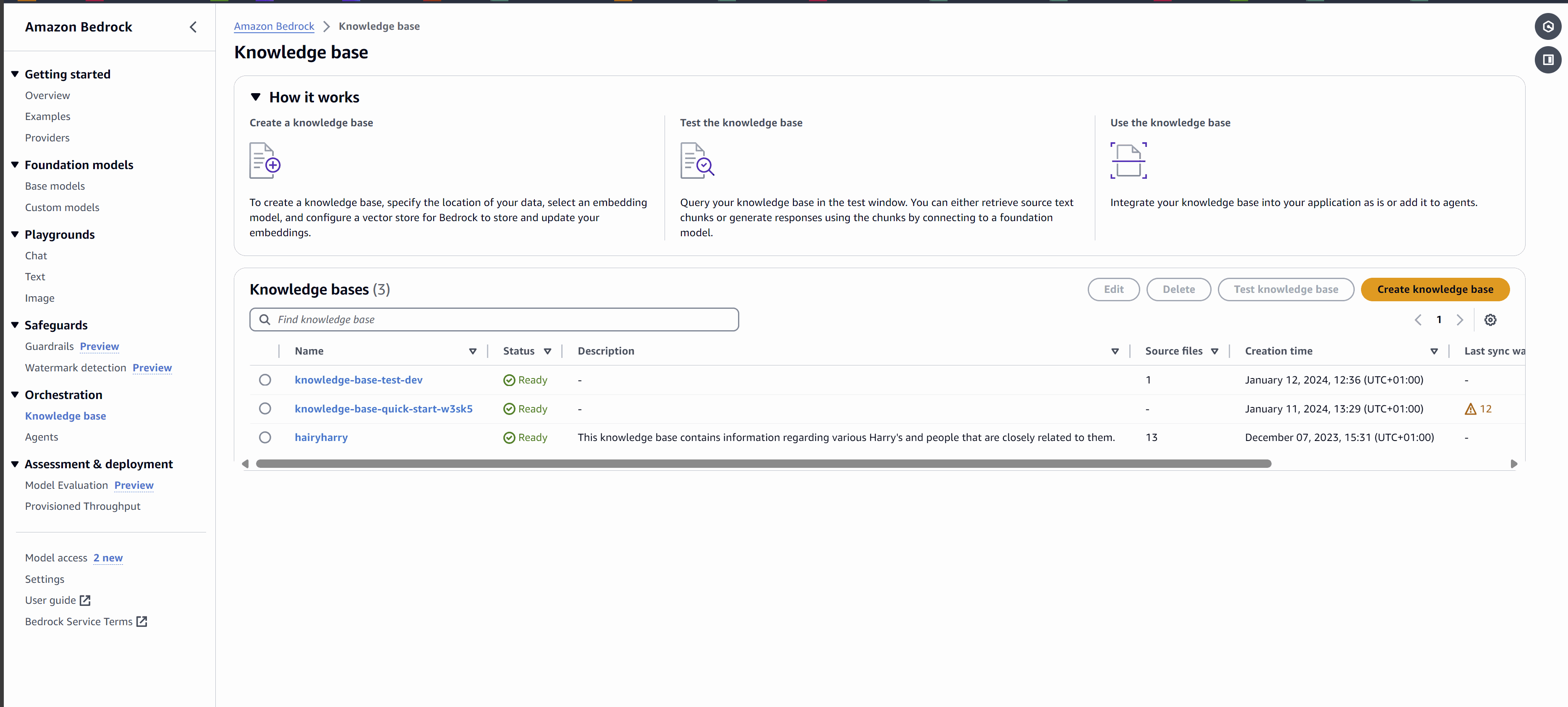
2. Im Seitenmenü unter dem Orchestrierung Abschnitt auswählen Wissensdatenbank, und klicken Sie dann auf Wissensbasis schaffen.

3. Benennen Sie Ihre Wissensdatenbank, wie im Screenshot oben gezeigt, und klicken Sie dann auf Weiter. Die anderen Felder können Sie als Standard belassen.
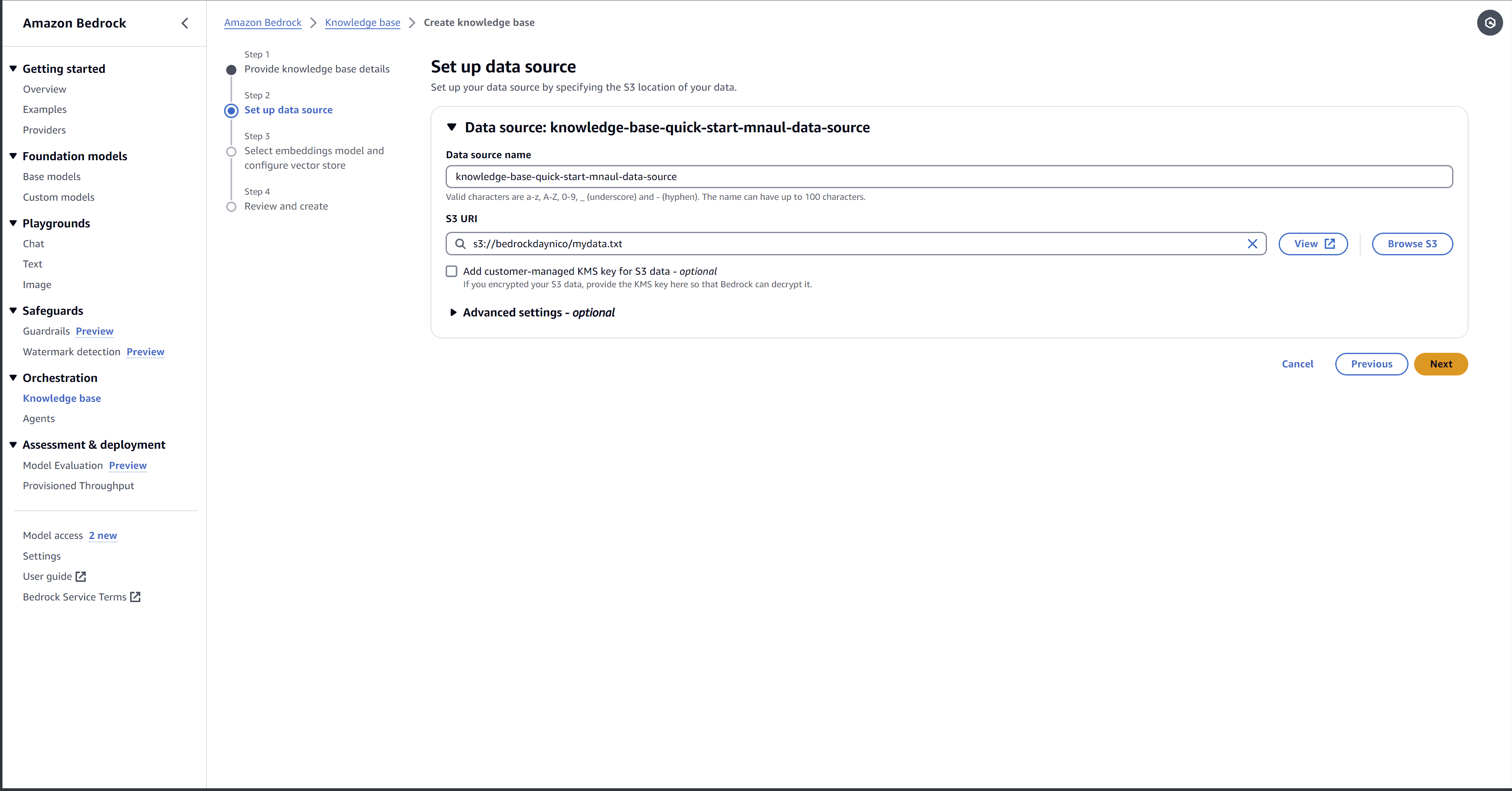
4. Swähle die S3 Eimer und a frustrierten Datei, Wie nachfolgend dargestellt.
5. Swählen das Einbettungsmodell zur Abwicklung, Integrierung, Speicherung und Sie möchten verwenden und dern Erstellen Sie eine neue Vektordatenbank, oder ein vorhandenes verwenden.
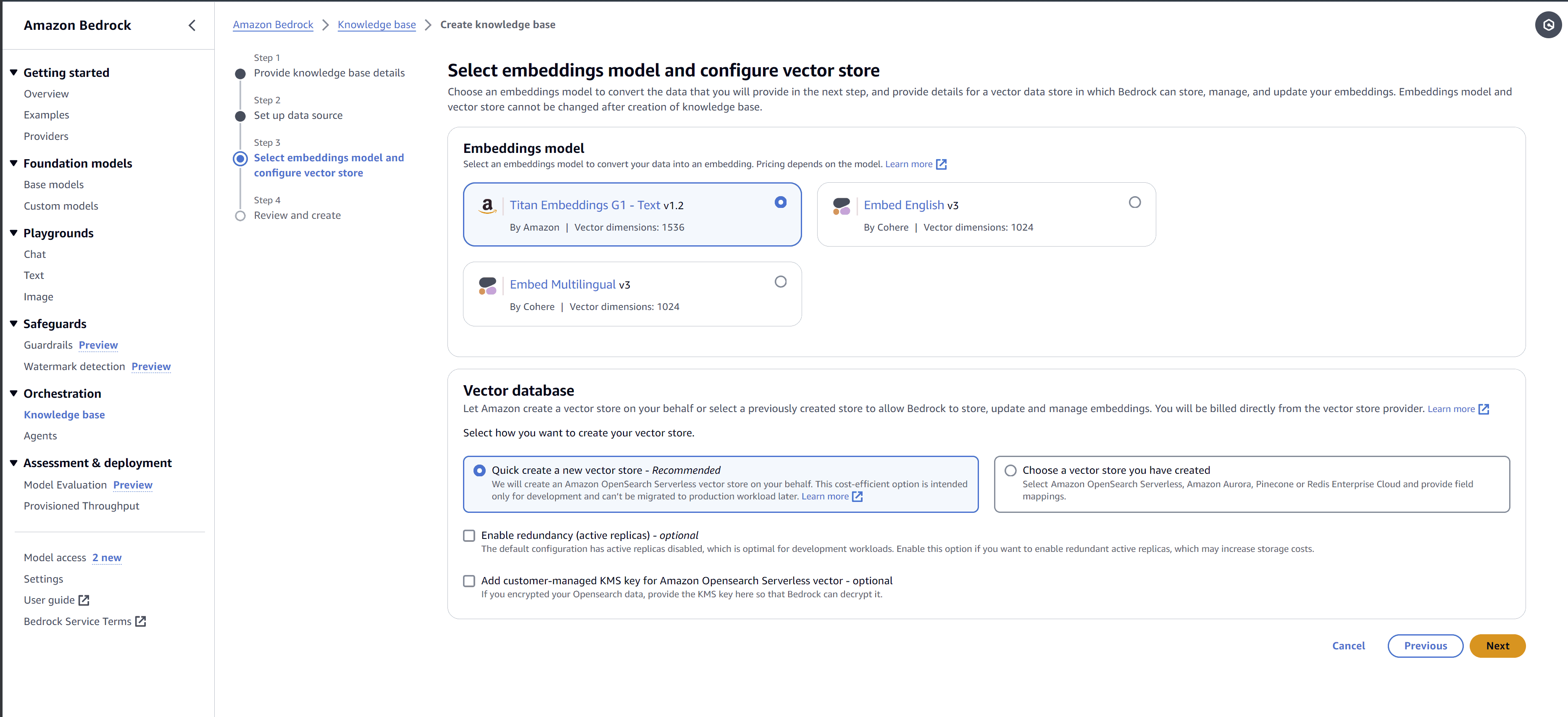
6. Überprüfen und erstellen Sie Ihre neue Datenbank.

Um zu demonstrieren, wie man die Wissensdatenbank mit einem Mendix app verwenden wir zwei Beispiele: eines mit der Aktion Abrufen und eines mit der Aktion Abrufen und Generieren. Wenn Sie mitmachen möchten, benötigen Sie eine Mendix App und die Mendix Amazon Bedrock Connector.
Alternativ können Sie sich auch die ansehen Amazon Bedrock Showcase App, das Ihnen zeigt, wie Sie mit dem Amazon Bedrock Connector mit verschiedenen Basismodellen experimentieren und diese mithilfe von Retrieval Augmented Generation (RAG) mit Ihren Daten anpassen können. Die App zeigt auch, wie Sie Agenten erstellen können, die Aufgaben mithilfe Ihrer eigenen Datenquellen ausführen.
Einrichten einer Abrufaktion
Zum Einrichten der Abrufaktion benötigen Sie die folgenden Entitäten.
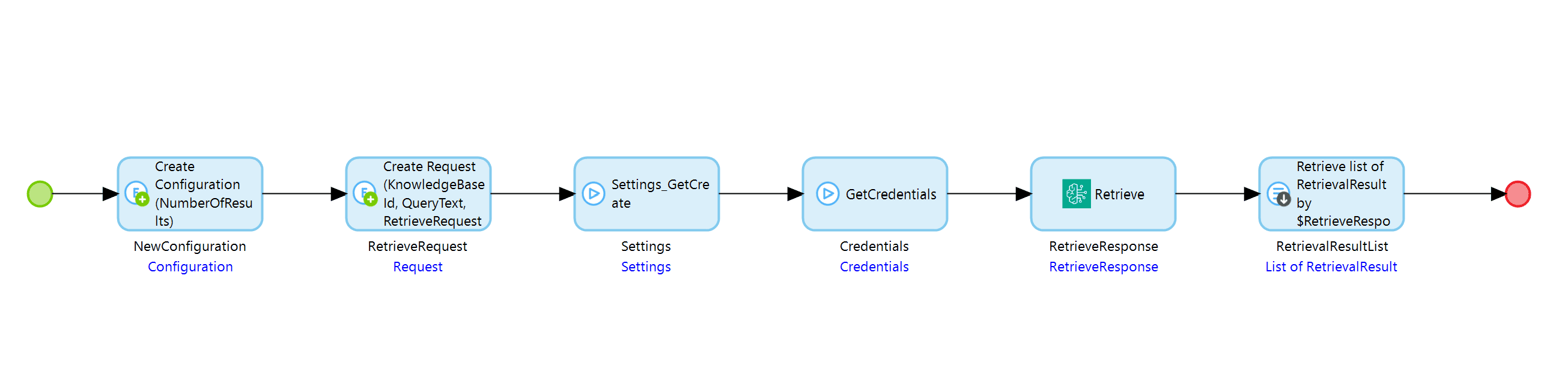
Die Retrieve-Anfrage benötigt eine Wissensdatenbank-ID, einen Abfragetext und eine Assoziation zum Konfigurationsobjekt.
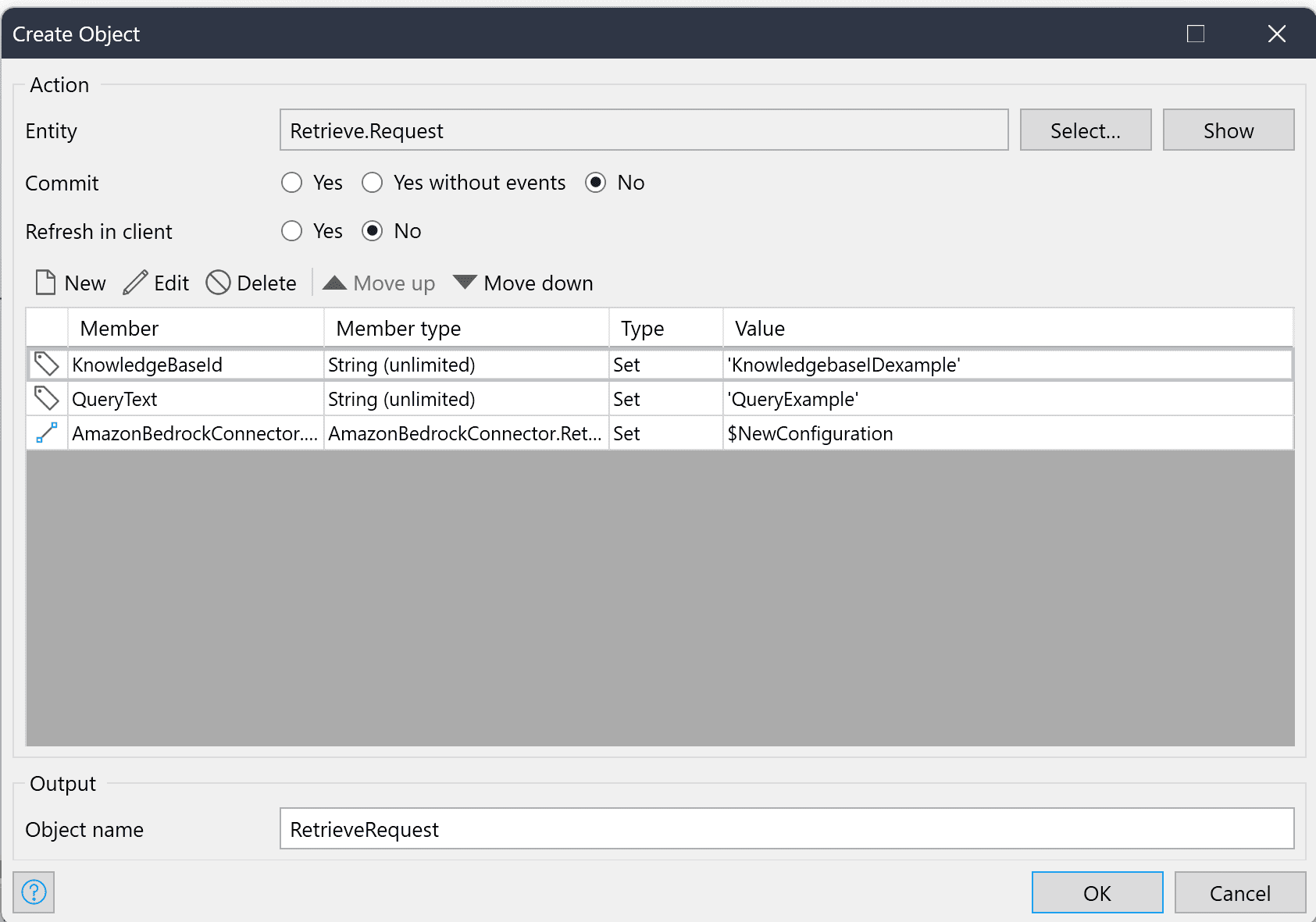
Das Konfigurationsobjekt sollte nur die Anzahl der Ergebnisse enthalten.
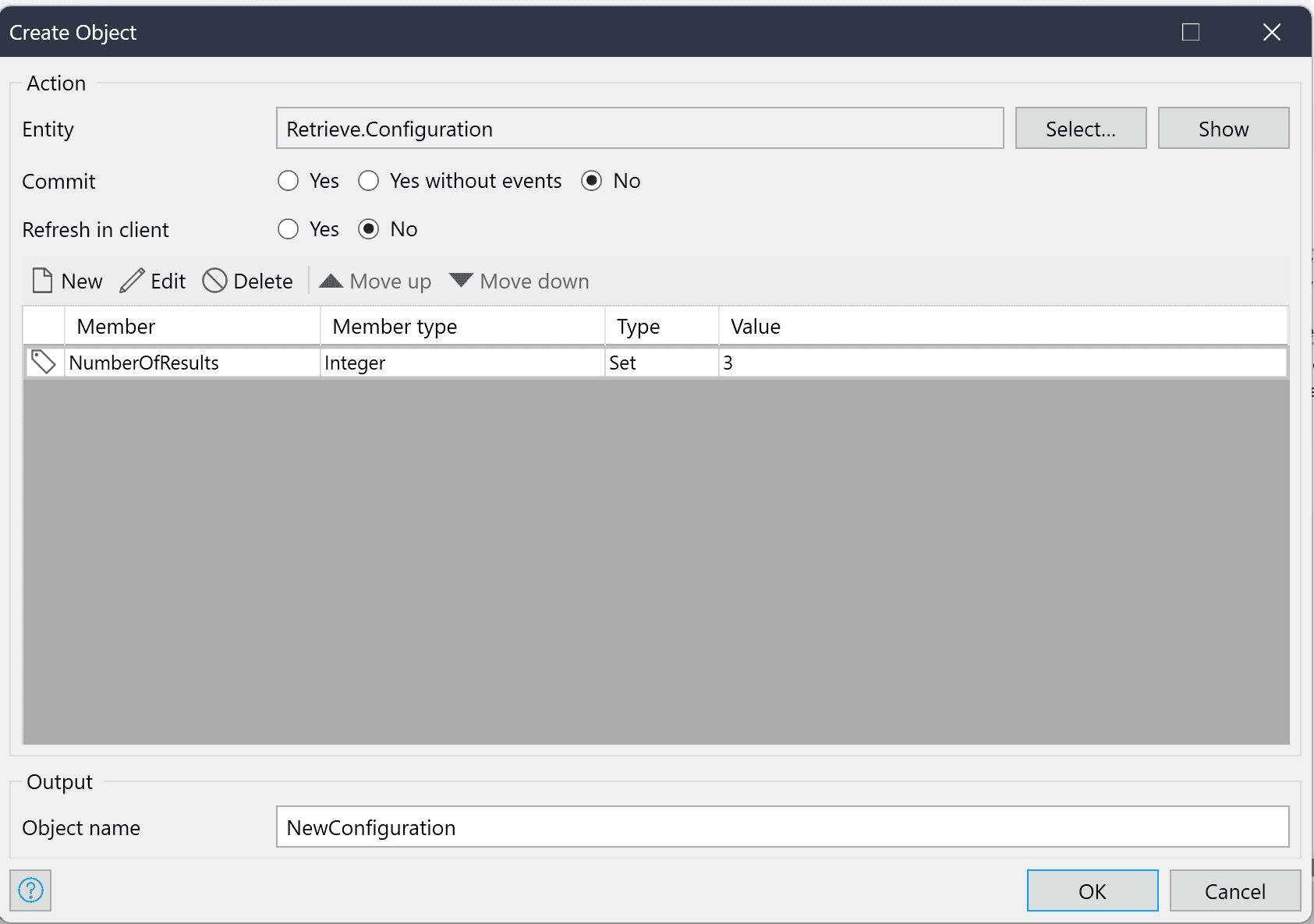
Der Vorgang gibt ein Objekt vom Typ RetrieveResponse zurück, das eine Liste von RetrievalResult-Objekten mit den aus der Wissensdatenbank abgerufenen Textblöcken enthält. Die Liste enthält maximal AnzahlErgebnisse Einträge, bei denen AnzahlErgebnisse ist die Nummer, die Sie im Konfigurationsobjekt angegeben haben.
Testen der Abruf- und Generierungsfunktionen Betrieb
Mithilfe des Amazon Bedrock Connectors können Sie Ihre zuvor eingerichtete Wissensdatenbank auch mit dem Vorgang „Abrufen und Generieren“ testen, indem Sie einen ähnlichen Mikrofluss wie den unten gezeigten einrichten:
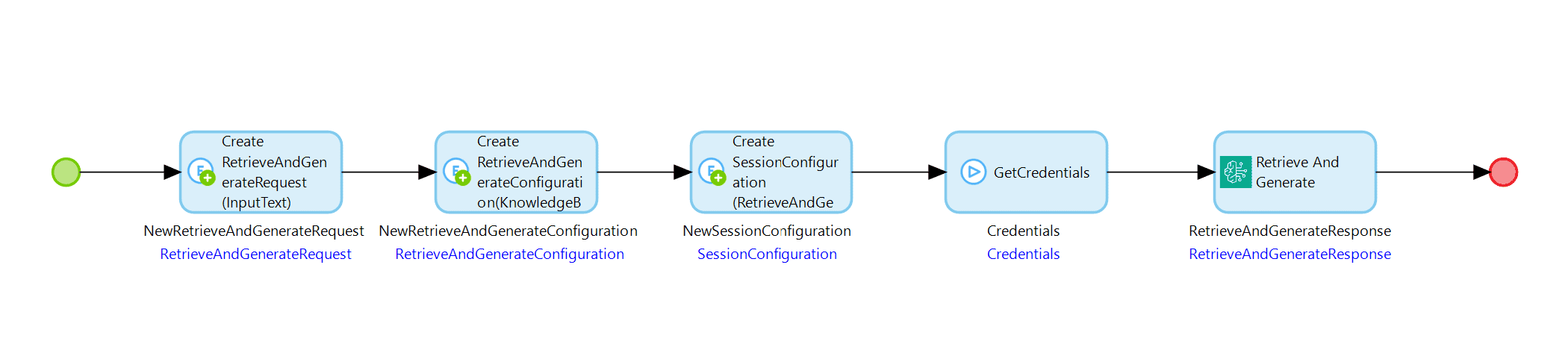
Die Objekte RetrieveAndGenerateRequest und RetrieveAndGenerateConfiguration sind erforderlich. Das Objekt SessionConfiguration ist ein optionales Objekt, das Sie der Anfrage hinzufügen können, wenn Sie einen KmsKeyArn hinzufügen müssen, um den Schlüssel zu beschreiben, der die Sitzung verschlüsselt. Sehen wir uns nun die Details der erforderlichen Objekte an.
Das RetrieveAndGenerateRequest-Objekt muss den Eingabetext enthalten, den Sie abfragen möchten, und optional eine Sitzungs-ID, wenn Sie eine laufende Sitzung fortsetzen möchten. Das RetrieveAndGenerateConfiguration-Objekt muss Ihre Wissensdatenbank-ID, die ModelARN des Modells, das Sie verwenden möchten, und einen Parameter namens RetrieveAndGenerateType enthalten, der derzeit nur den Enumerationswert „KNOWLEDGE_BASE“ haben kann, der während der Erstellung des Objekts festgelegt wird. Die Zuordnung zwischen diesen Objekten muss auch im RetrieveAndGenerateConfiguration-Objekt festgelegt werden.
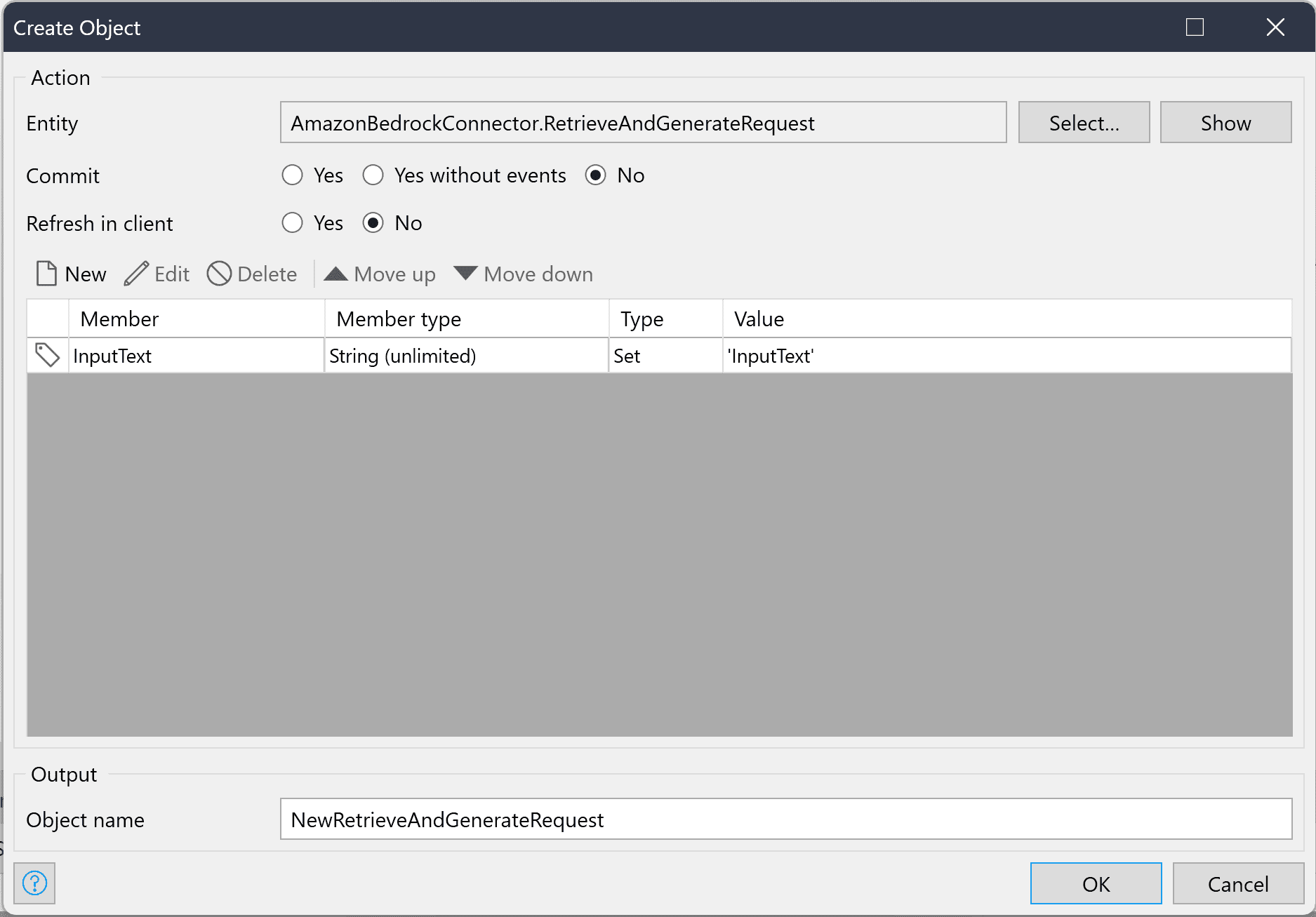
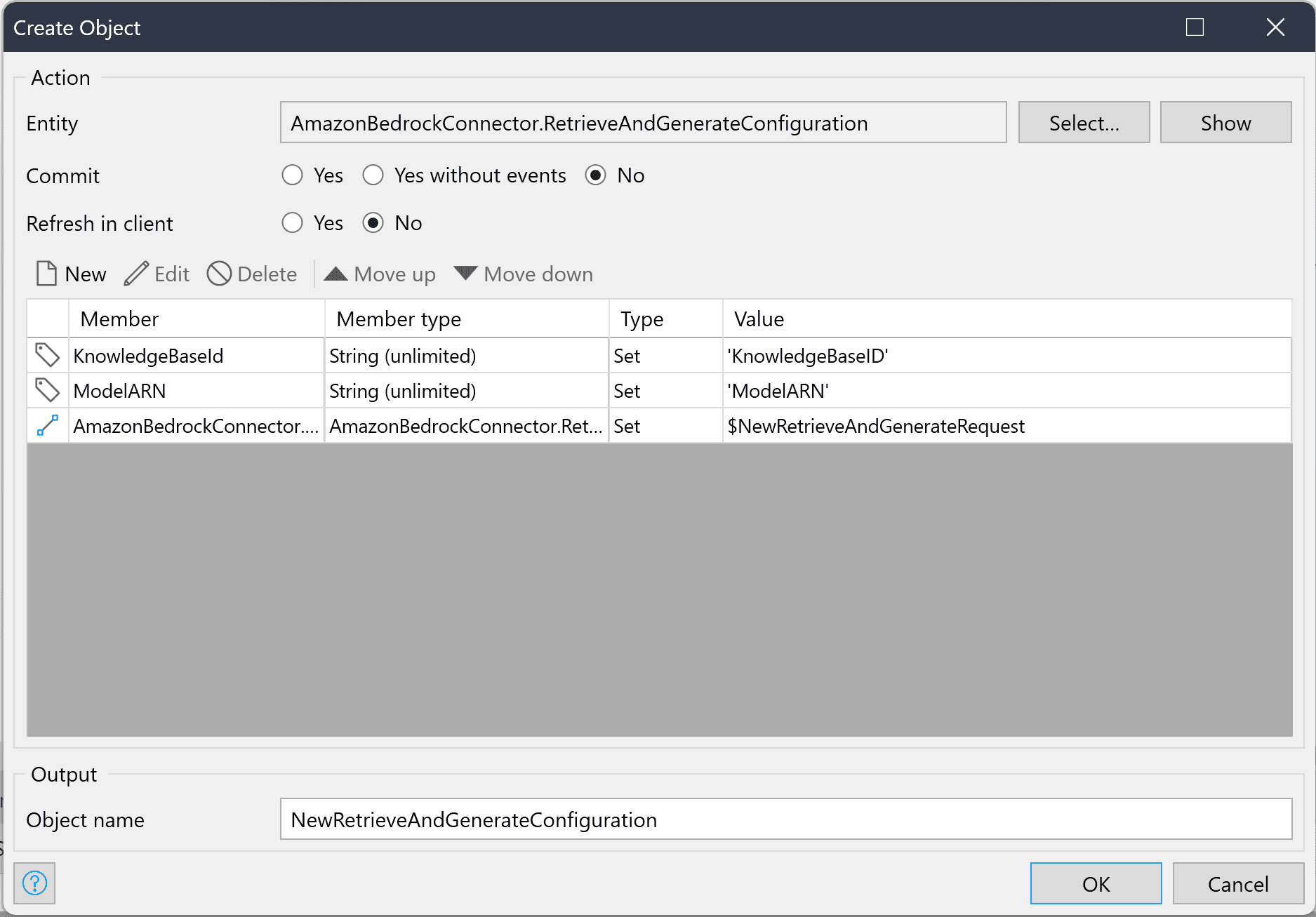
Das RetrieveAndGenerateResponse-Objekt gibt einen Ausgabetext zurück, der zur Beantwortung Ihrer Abfrage unter Verwendung der Informationen in Ihrer Wissensdatenbank generiert wird. Dem Antwortobjekt ist außerdem eine Liste von Citation-Objekten zugeordnet, in der Sie Informationen zu den abgerufenen Referenzen und den während der Ausgabegenerierung verwendeten Teilen finden können.
Gehen wir noch einen Schritt weiter
Um die Operationen „Abrufen und Generieren“ und „Modell aufrufen“ noch besser zu nutzen, strukturieren Sie Ihre Abfragen detaillierter, um bessere Antworten auf Ihre Fragen zu erhalten. Prompt Engineering ist die Kunst, Eingabeaufforderungen zu schreiben, die zu besseren Antworten führen. Mit Prompt Engineering können Sie einschränken, fokussieren, und passen Sie die zu erwartenden Antworten an. Sie können beispielsweise der Benutzereingabeaufforderung zusätzliche Daten hinzufügen, die vom Modell verwendet werden sollen. Auf diese Weise können Sie bessere Abfragen in der Wissensdatenbank und Ihrem LLM durchführen, um eine Antwort in dem Stil zu generieren, der für Ihren Anwendungsfall von Vorteil ist.
Abrufen und Generieren im Vergleich zu Amazon Bedrock Agents
Sie fragen sich vielleicht, ob Sie in Ihrer Anwendung „Abrufen und Generieren“ oder „Agent aufrufen“ verwenden sollen. Um Ihnen einen umfassenden Überblick über diese beiden Vorgänge zu geben, sehen wir uns an, was bei diesen beiden Vorgängen passiert.
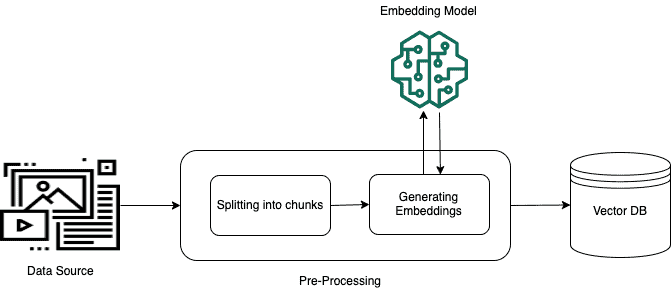
Wenn Sie Ihre Dokumente zu einer Wissensdatenbank hinzufügen und synchronisieren, werden Ihre Dokumente zunächst in Blöcke aufgeteilt (natürlich nur, wenn Sie eine Blockmethode konfiguriert haben). Anschließend werden diese Blöcke mithilfe eines Einbettungsmodells konvertiert und in einen Vektorspeicher geschrieben. Während dieses Vorgangs werden die angegebenen Vektorindizes jedem Block zugeordnet, sodass das Modell bei Bedarf die relevantesten Blöcke finden kann.
Obwohl diese Vektordarstellungen eine Folge von Zahlen (Einbettungen) sind, die für uns vielleicht keine Bedeutung haben, enthalten sie eine Menge Bedeutung für das Einbettungsmodell. Denken Sie also nicht, dass sie nur Kauderwelsch sind. Die Vektordatenbank, in der diese Einbettungen gespeichert sind, ist eine entscheidende Komponente bei der Verwendung aller Operationen mit Wissensbasen. Sie können sich das Bild unten ansehen, um eine Illustration der Vorverarbeitung von Daten für die Vektordatenbank zu sehen, die wir in der offiziellen Amazon Bedrock-Dokumentation.
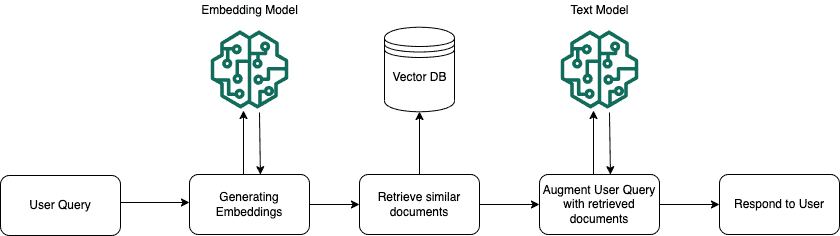
Die folgende Abbildung veranschaulicht die Operationen „Abrufen“ und „Abrufen und Generieren“. Wenn eine Benutzerabfrage mithilfe der Operationen „Abrufen“ oder „Abrufen und Generieren“ gestellt wird, wird diese Abfrage mithilfe desselben Einbettungsmodells wie bei der Erstellung der Wissensdatenbank in einen Vektor konvertiert.
Anschließend wird die der Benutzerabfrage zugewiesene Vektordarstellung mit den Vektoren in der Vektordatenbank verglichen, um die Blöcke mit semantischer Ähnlichkeit zu finden. Anschließend werden die Blöcke mit ähnlicher Ähnlichkeit lokalisiert und an den Benutzer zurückgegeben. Dieser Teil des Prozesses läuft bis zur roten Linie, die im Bild unten zu sehen ist und den Abrufvorgang beschreibt.
Anschließend werden die konvertierten Texte mit der Benutzerabfrage an ein Textmodell übergeben, um eine Antwort für den Benutzer zu generieren. Dies alles erklärt den Abruf- und Generierungsvorgang.
Möglicherweise sind nicht alle Basismodelle eine Funktion der Funktion „Abrufen und Generieren“ in Amazon Bedrock, wenn Sie die Funktion verwenden möchten. Ich bin mir jedoch sicher, dass die meisten von uns irgendwann einmal eine Problemumgehung finden mussten, wenn Plan A nicht so gut funktionierte wie gedacht. Daher haben wir als Entwicklerkollegen auch eine Problemumgehung entwickelt, um eine ähnliche Funktion mit jedem in Amazon Bedrock verfügbaren Basismodell verwenden zu können.
Wie oben erläutert, ruft der Vorgang „Abrufen und Generieren“ relevante Informationen aus Ihrer Wissensdatenbank ab. Diese Informationen werden dann mit der Benutzerabfrage an ein Textmodell übergeben, um eine Antwort zu generieren. Diese Funktion kann in zwei separaten Schritten repliziert und abgeschlossen werden.
Verwenden Sie zunächst den Abrufvorgang, um relevante Informationen aus Ihrer Wissensdatenbank abzurufen. Verwenden Sie dann den Vorgang „Modell aufrufen“ mit einer Folgeabfrage, die die empfangenen relevanten Informationen sowie Ihre ursprüngliche Frage enthält. Die Verwendung dieser Methode bedeutet, dass Sie den JSON-Anforderungstext für den Vorgang „Modell aufrufen“ selbst erstellen müssen. Sie können jedoch jedes beliebige von Amazon Bedrock bereitgestellte Basismodell verwenden.
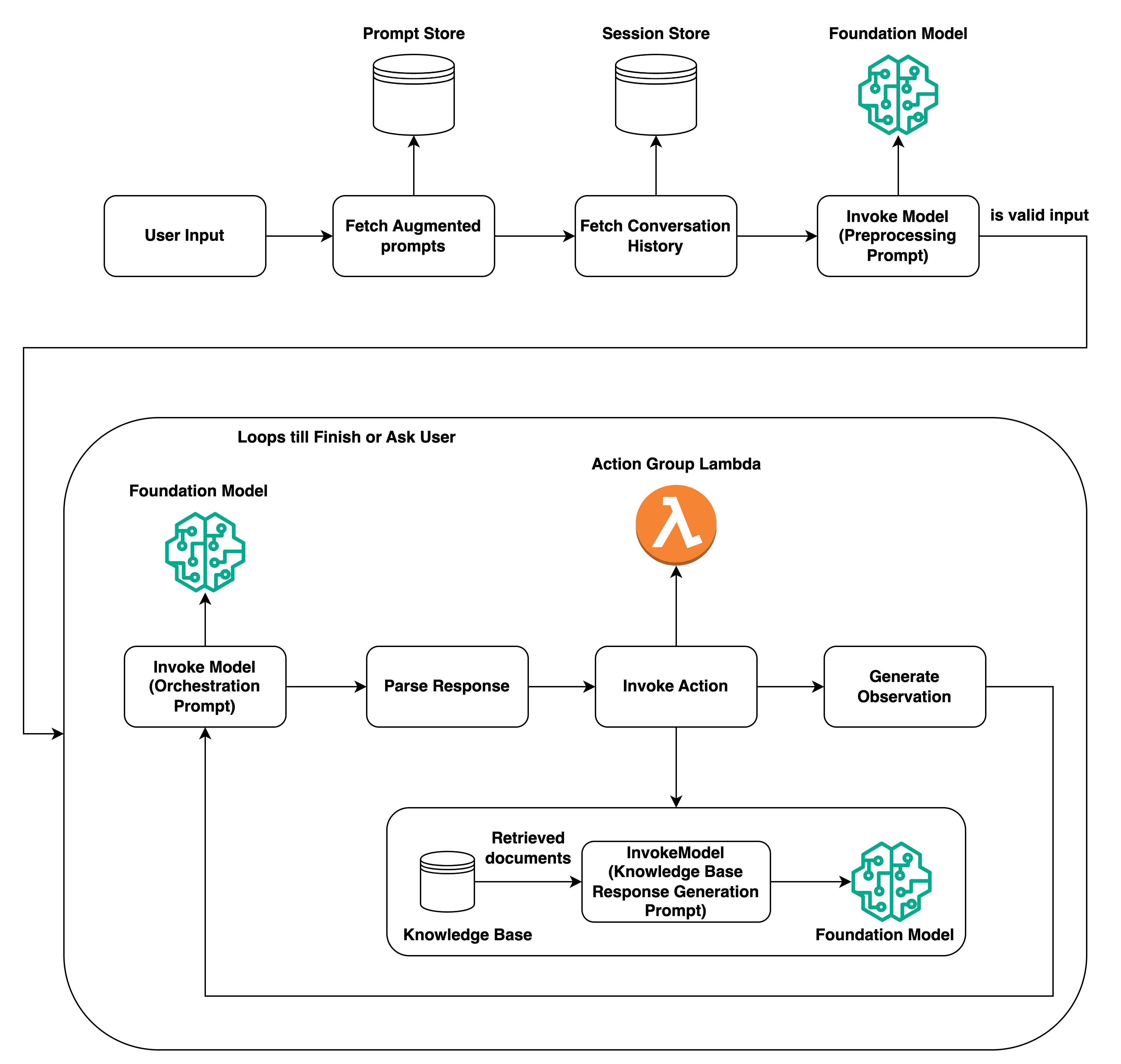
Lassen Sie uns nun sehen, wie sich das Aufrufen eines Agenten unterscheidet, indem Sie sich die ausführliche Abbildung unten ansehen. Amazon Bedrock Agents-Dokumentation.
Der Vorgang beginnt mit einer Benutzereingabe. Vor allem anderen werden die erweiterten Eingabeaufforderungen, die während der Vorverarbeitung, Orchestrierung, Generierung von Antworten aus der Wissensdatenbank und der Nachverarbeitungsschritte verwendet werden, aus dem Eingabeaufforderungsspeicher abgerufen.
Wenn Sie den Vorgang „Agent aufrufen“ schon einmal verwendet haben, denken Sie vielleicht: „Prompt-Store? Ich habe keine Prompts erstellt, aber der Vorgang funktioniert irgendwie…?“.\ Nun, in diesem Fall hätten Sie Recht, denn Amazon Bedrock hat Standardprompts, die für diese von Anfang an konfigurierten Schritte verwendet werden. Diese Prompts sind jedoch vollständig konfigurierbar, um den Anforderungen Ihrer Anwendung zu entsprechen, was eines der Features ist, das die Flexibilität der Agents in Amazon Bedrock zeigt. Wenn Sie dann den Verlauf der Konversation für die Abfrage im Auge behalten möchten, wird der Verlauf gemäß der Sitzung abgerufen, bevor der Vorverarbeitungsprompt – ausgefüllt mit den abgerufenen Informationen und Ihrer Abfrage – an das Basismodell gesendet wird. Wenn die Abfrage als gültige Eingabe akzeptiert wird, beginnt die in der Abbildung gezeigte Schleife.
Der Vorgang wird in die Schleife fortgesetzt und verwendet die vorherigen Informationen, um die konfigurierte Orchestrierungsaufforderung auszufüllen und das Basismodell aufzurufen. Gemäß der analysierten Antwort wird der Abschnitt „Aktion aufrufen“ der Abbildung in Gang gesetzt. Was diese Aktion sein wird, hängt ganz von der Anordnung des Benutzers ab.
Im Gegensatz zu „Retrieve“ und „Generate“ können Agenten verschiedene Vorgänge mithilfe mehrerer Wissensdatenbanken ausführen und sogar Aufgaben mithilfe von Lambda-Funktionen orchestrieren. Die Möglichkeiten sind endlos und nicht darauf beschränkt, nur die Ausgabe zurückzuerhalten. Der Vorgang kann so eingerichtet werden, dass er in einer Schleife weiterläuft, bis ein gewünschtes Ergebnis gefunden wird oder eine gewünschte Aktion ausgeführt wird, indem die Funktionen von Amazon Bedrock-Agenten genutzt werden. Was genau diese Aktionen sein können … Nun, ich denke, das überlassen wir einem zukünftigen Blog!
Erkundung der KI-Anpassung mit Amazon Bedrock und Mendix
In diesem Beitrag haben wir uns mit dem spannenden Bereich der Anpassung von Basismodellen mit benutzerdefinierten Daten unter Verwendung von Amazon Bedrock befasst und Mendix. Mit der neuen Funktionalität von AWS ist es jetzt einfacher denn je, benutzerdefinierte Daten in grundlegende Modelle zu integrieren, Eingabeaufforderungen zu erweitern und relevantere Antworten zu generieren. In Schritt-für-Schritt-Anleitungen haben wir gezeigt, wie man eine Wissensdatenbank einrichtet, Daten aufnimmt und nutzt Mendix Anwendungen mit dem Amazon Bedrock-Connector, um die Leistung dieser Techniken zu nutzen.
Darüber hinaus haben wir die Operationen „Retrieve and Generate“ und „Invoke Agent“ verglichen und ihre Unterschiede und Fähigkeiten herausgearbeitet. Während „Retrieve and Generate“ einen optimierten Ansatz zum Abrufen von Informationen und Generieren von Antworten bietet, bietet „Invoke Agent“ mehr Flexibilität und ermöglicht die Orchestrierung von Aufgaben mithilfe mehrerer Wissensdatenbanken, Lambda-Funktionen und mehr.
Entdecken Sie unsere Amazon Bedrock Showcase App, um einen Überblick über alle derzeit mit dem Amazon Bedrock Connector möglichen Operationen zu erhalten. Mit Amazon Bedrock und Mendix, die Möglichkeiten sind endlos. Wir kratzen gerade erst an der Oberfläche dessen, was im Bereich der KI-Anpassung und -Integration erreicht werden kann.
Dieser Blogbeitrag wurde von Agapi mitverfasst Karafoulidou und Ayça Öner.