 In Mendix 문자열의 길이는 얼마인가요?
In Mendix 문자열의 길이는 얼마인가요?
-
 에이드리언 프레스턴
에이드리언 프레스턴

- 2022 년 12 월 15 일
- 11분 읽기

![]() 이것은 효율성에 대한 내 블로그 시리즈의 두 번째입니다. Mendix 앱. 시리즈의 첫 번째(
이것은 효율성에 대한 내 블로그 시리즈의 두 번째입니다. Mendix 앱. 시리즈의 첫 번째(![]() 건강과 효율성 Mendix
건강과 효율성 Mendix![]() ), 저는 로우코드의 효율성을 개선할 수 있는 간단한 방법 몇 가지를 강조했습니다. 이제 더 어려운 것을 다루어보겠습니다.
), 저는 로우코드의 효율성을 개선할 수 있는 간단한 방법 몇 가지를 강조했습니다. 이제 더 어려운 것을 다루어보겠습니다.
![]() 지난 5년 동안 두 번이나, 기본적으로 모든 데이터를 검토해서 텍스트 파일을 만들어야 하는 요구사항을 처리해야 했습니다.
지난 5년 동안 두 번이나, 기본적으로 모든 데이터를 검토해서 텍스트 파일을 만들어야 하는 요구사항을 처리해야 했습니다.
![]() 첫 번째는 데이터 집합을 나타내는 탭으로 구분된 텍스트 파일을 생성하는 것이었습니다. Mendix 앱. 두 번째는 앱에서 빌드된 데이터 집합에서 Typescript 파일을 생성해야 했습니다. 이 두 가지 모두
첫 번째는 데이터 집합을 나타내는 탭으로 구분된 텍스트 파일을 생성하는 것이었습니다. Mendix 앱. 두 번째는 앱에서 빌드된 데이터 집합에서 Typescript 파일을 생성해야 했습니다. 이 두 가지 모두 ![]() 매우 긴 텍스트 파일 생성을 지원해야 함
매우 긴 텍스트 파일 생성을 지원해야 함![]() 데이터 집합이 매우 클 수 있기 때문입니다.
데이터 집합이 매우 클 수 있기 때문입니다.
![]() 오늘날 Marketplace에는 훌륭한 모듈이 많이 있습니다(예:
오늘날 Marketplace에는 훌륭한 모듈이 많이 있습니다(예: ![]() CSV
CSV![]() CSV/TSV 파일 생성에는 도움이 되는 모듈이 있지만, 더 임의의 텍스트 출력에는 대체 솔루션이 필요합니다.
CSV/TSV 파일 생성에는 도움이 되는 모듈이 있지만, 더 임의의 텍스트 출력에는 대체 솔루션이 필요합니다.

테스트 연습
![]() 비교를 위한 통계를 수집하기 위해 저는 다음 앱을 사용하고 있습니다.
비교를 위한 통계를 수집하기 위해 저는 다음 앱을 사용하고 있습니다. ![]() Mendix 9.15.1
Mendix 9.15.1![]() ,에 배치됨
,에 배치됨 ![]() 중간 사이즈
중간 사이즈![]() 환경 (
환경 ( ![]() 최대 2개 CPU, 최대 2GB 메모리, Postgres 데이터베이스
최대 2개 CPU, 최대 2GB 메모리, Postgres 데이터베이스![]() )에서 실행 중
)에서 실행 중 ![]() AWS EKS 프라이빗 Mendix 클라우드
AWS EKS 프라이빗 Mendix 클라우드![]() 어느 포함
어느 포함 ![]() 그라 파나
그라 파나![]() 모니터링.
모니터링.
![]() 각 운동은
각 운동은 ![]() 5번 달리다
5번 달리다![]() . 5가지 운동의 각 세트를 실행하기 전에
. 5가지 운동의 각 세트를 실행하기 전에![]() 앱이 중지되었다가 다시 시작되었습니다
앱이 중지되었다가 다시 시작되었습니다![]() 가능한 최소화하기 위해
가능한 최소화하기 위해 ![]() 캐싱
캐싱![]() 결과에 영향을 미칩니다.
결과에 영향을 미칩니다. ![]() 가장 좋은 결과와 가장 나쁜 결과는 삭제됩니다.
가장 좋은 결과와 가장 나쁜 결과는 삭제됩니다.![]() 그리고
그리고 ![]() 나머지 세 개는 평균화됩니다
나머지 세 개는 평균화됩니다![]() . 연습은 반드시 여기에 제시된 순서대로 진행되는 것은 아닙니다.
. 연습은 반드시 여기에 제시된 순서대로 진행되는 것은 아닙니다.
![]() 사용된 앱은 GitHub에서 사용 가능합니다.
사용된 앱은 GitHub에서 사용 가능합니다. ![]() LINK.
LINK.
시작점
![]() 우리는 목록이 있습니다 Mendix 객체가 있고, 그 객체 중 하나에서 원하는 텍스트를 생성하는 마이크로플로가 있습니다. 간단하게 하기 위해 단일 데이터 엔터티로 작업하겠지만 실제 시나리오에서는 큰 객체 트리가 관련될 수 있습니다.
우리는 목록이 있습니다 Mendix 객체가 있고, 그 객체 중 하나에서 원하는 텍스트를 생성하는 마이크로플로가 있습니다. 간단하게 하기 위해 단일 데이터 엔터티로 작업하겠지만 실제 시나리오에서는 큰 객체 트리가 관련될 수 있습니다. ![]() OutputDocument는 문자열 생성 프로세스의 결과를 수신하는 FileDocument 특수화입니다..
OutputDocument는 문자열 생성 프로세스의 결과를 수신하는 FileDocument 특수화입니다..
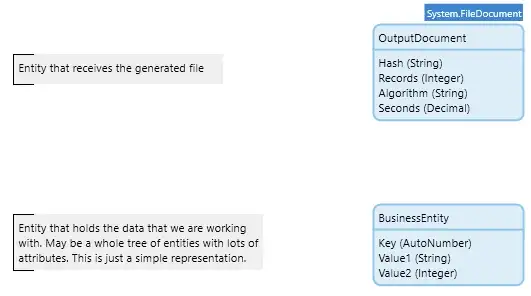
 도메인 모델의 비즈니스 엔터티 및 출력 문서
도메인 모델의 비즈니스 엔터티 및 출력 문서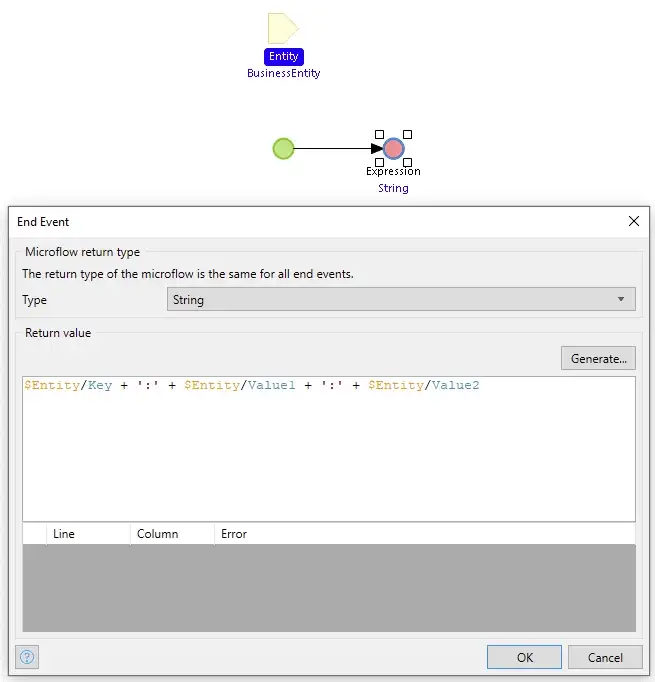 BusinessEntity 인스턴스에 대한 텍스트를 생성하는 GetEntityToString 마이크로플로
BusinessEntity 인스턴스에 대한 텍스트를 생성하는 GetEntityToString 마이크로플로![]() 출력 파일을 생성하기 위해 2,500개 레코드의 배치로 데이터 레코드를 끌어내고, 객체 목록을 전달하고, 각각에 대해 생성된 텍스트를 크기가 커지는 컬렉션 문자열에 추가합니다. 목록이 고갈되면 축적한 문자열이 OutputDocument에 기록됩니다. 생성된 OutputDocument는 사용된 알고리즘, 처리된 레코드 수, 테스트를 실행하는 데 걸린 시간, 생성된 파일의 해시도 기록합니다. 해시가 생성되어 저장되므로 동일한 출력을 생성하는 데 사용된 모든 메서드가 동일한 소스 데이터에서 나온 것인지 확인할 수 있습니다.
출력 파일을 생성하기 위해 2,500개 레코드의 배치로 데이터 레코드를 끌어내고, 객체 목록을 전달하고, 각각에 대해 생성된 텍스트를 크기가 커지는 컬렉션 문자열에 추가합니다. 목록이 고갈되면 축적한 문자열이 OutputDocument에 기록됩니다. 생성된 OutputDocument는 사용된 알고리즘, 처리된 레코드 수, 테스트를 실행하는 데 걸린 시간, 생성된 파일의 해시도 기록합니다. 해시가 생성되어 저장되므로 동일한 출력을 생성하는 데 사용된 모든 메서드가 동일한 소스 데이터에서 나온 것인지 확인할 수 있습니다.
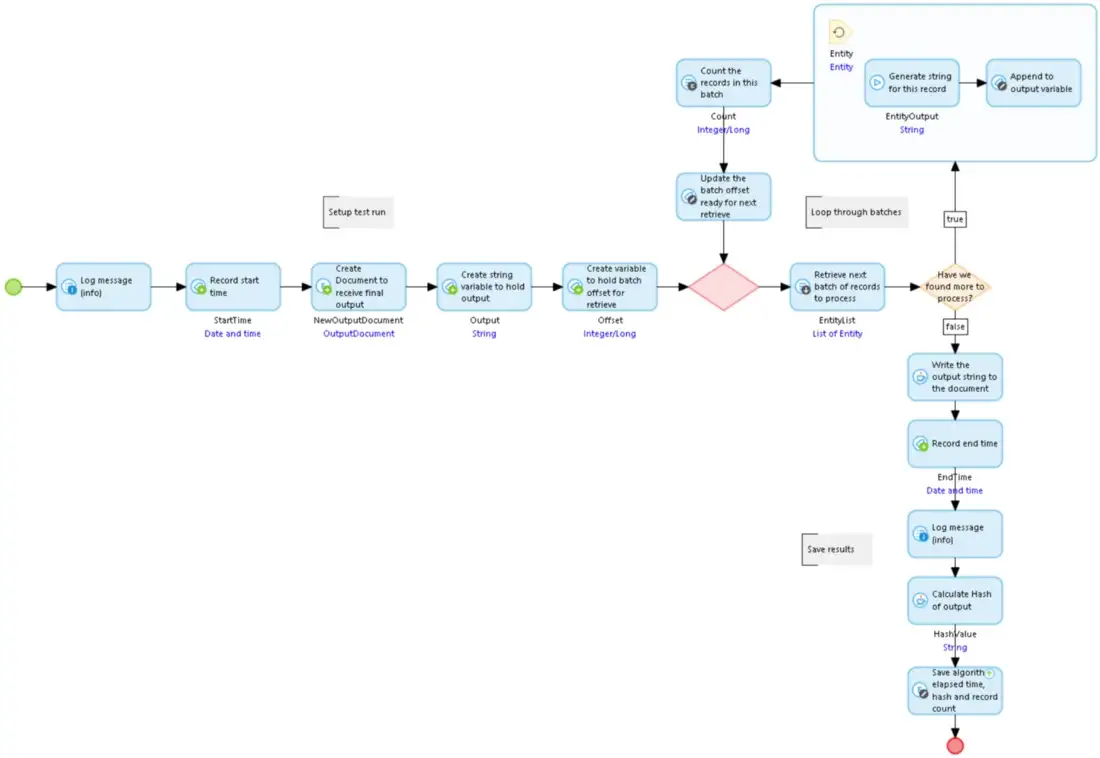 시작점 빌드 문자열 마이크로 흐름
시작점 빌드 문자열 마이크로 흐름그럼, 실행해 볼까요.
![]() 나는 데이터베이스를 프라이밍합니다
나는 데이터베이스를 프라이밍합니다 ![]() 25,000 레코드
25,000 레코드![]() '무작위' 텍스트 문자열을 사용하여
'무작위' 텍스트 문자열을 사용하여 ![]() 각 500자
각 500자![]() 그리고 무작위 정수 값을 입력한 후 위의 마이크로플로를 실행합니다.
그리고 무작위 정수 값을 입력한 후 위의 마이크로플로를 실행합니다.

![]() 그것은 우리에게 평균을 제공합니다 78.81
그것은 우리에게 평균을 제공합니다 78.81![]() 문자열을 빌드하고 FileDocument에 저장하는 데 몇 초가 걸립니다. 이제
문자열을 빌드하고 FileDocument에 저장하는 데 몇 초가 걸립니다. 이제 ![]() 데이터를 두 배로 늘리다
데이터를 두 배로 늘리다![]() 크기 50,000
크기 50,000![]() 레코드를 다시 실행하고 마이크로플로를 다시 실행합니다. 200초 이내에 걸릴 것으로 예상할 수 있습니다. 최소한 레코드 볼륨이 증가했기 때문에 배치된 검색이 더 느려질 것이라고 가정해야 하지만 키에 인덱스가 있습니다.
레코드를 다시 실행하고 마이크로플로를 다시 실행합니다. 200초 이내에 걸릴 것으로 예상할 수 있습니다. 최소한 레코드 볼륨이 증가했기 때문에 배치된 검색이 더 느려질 것이라고 가정해야 하지만 키에 인덱스가 있습니다.

![]() 오 와! 그래서 그게
오 와! 그래서 그게 ![]() 평균 334.05초
평균 334.05초![]() . 실행되는 동안 볼 영화가 한두 편 있지 않는 한, 정말 큰 데이터 집합은 시도하지 않을 겁니다…
. 실행되는 동안 볼 영화가 한두 편 있지 않는 한, 정말 큰 데이터 집합은 시도하지 않을 겁니다…
![]() 그러면 데이터 양이 두 배로 늘어나면 경과 시간도 4배 늘어나는 이유는 무엇일까요?
그러면 데이터 양이 두 배로 늘어나면 경과 시간도 4배 늘어나는 이유는 무엇일까요?
![]() 프로파일링 도구를 사용하지 않고는 완벽하게 확신할 수는 없지만, 주범이 누구인지에 대해 지적인 추측을 할 수는 있습니다.
프로파일링 도구를 사용하지 않고는 완벽하게 확신할 수는 없지만, 주범이 누구인지에 대해 지적인 추측을 할 수는 있습니다.
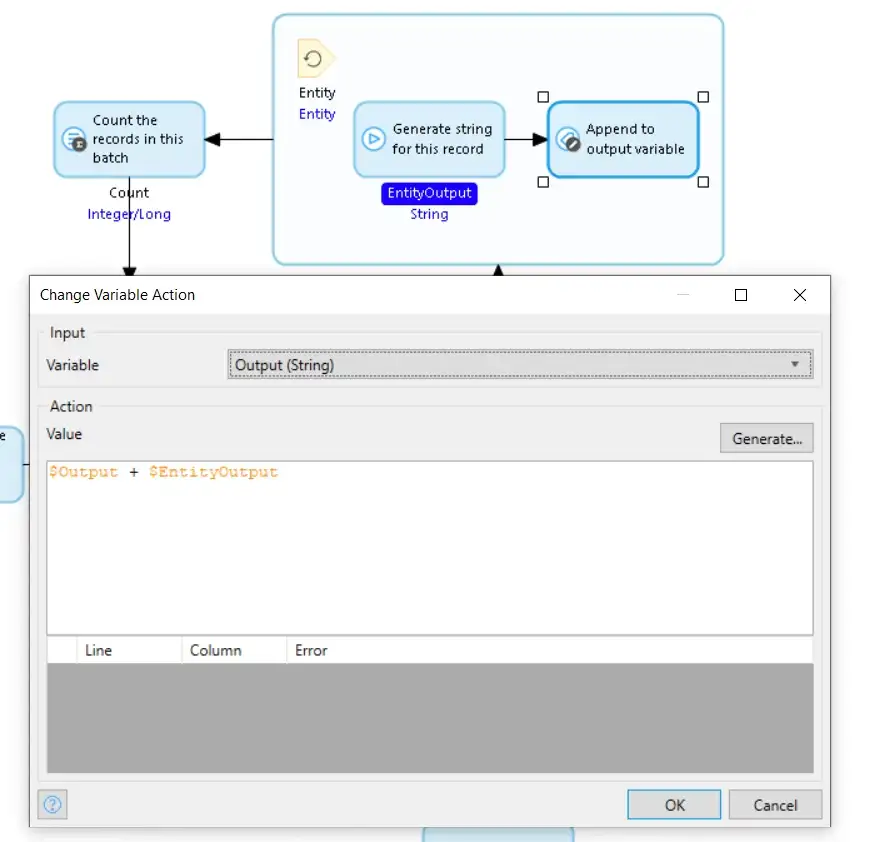 TheStartingPointBuildString 발췌
TheStartingPointBuildString 발췌![]() Change Variable 작업은 GetEntityToString 하위 마이크로플로에서 반환된 문자열을 Output 변수에 이미 저장된 이전 결과에 추가합니다. 다만 정확히 그렇게 하지는 않습니다.
Change Variable 작업은 GetEntityToString 하위 마이크로플로에서 반환된 문자열을 Output 변수에 이미 저장된 이전 결과에 추가합니다. 다만 정확히 그렇게 하지는 않습니다. ![]() In Mendix 문자열은 변경할 수 없습니다
In Mendix 문자열은 변경할 수 없습니다![]() 따라서 Output 변수에 대한 새 값을 생성하려면
따라서 Output 변수에 대한 새 값을 생성하려면 ![]() Mendix 새로운 문자열을 생성해야 합니다
Mendix 새로운 문자열을 생성해야 합니다![]() 구성
구성 ![]() 원본의 사본
원본의 사본![]() EntityOutput의 복사본을 추가한 Output을 생성하고, 이전 Output 값 대신 새 문자열을 저장합니다. 이전 Output 값은 삭제됩니다.
EntityOutput의 복사본을 추가한 Output을 생성하고, 이전 Output 값 대신 새 문자열을 저장합니다. 이전 Output 값은 삭제됩니다.
![]() Output의 값이 길어질수록 복사되는 텍스트의 양이 늘어납니다.
Output의 값이 길어질수록 복사되는 텍스트의 양이 늘어납니다.![]() , 그리고 그 과정은 점점 더 많은 시간과 자원을 필요로 하게 됩니다.
, 그리고 그 과정은 점점 더 많은 시간과 자원을 필요로 하게 됩니다.
![]() 그러니 조금 리엔지니어링을 시도해 봅시다.
그러니 조금 리엔지니어링을 시도해 봅시다. ![]() 일부 Java 코드 사용
일부 Java 코드 사용![]() 긴 문자열을 반복적으로 복사하는 것을 피하고 실행 시간을 줄일 수 있는지 확인해 보세요.
긴 문자열을 반복적으로 복사하는 것을 피하고 실행 시간을 줄일 수 있는지 확인해 보세요.
메모리 버퍼
![]() 긴 문자열을 만드는 대신 Mendix 가변 문자열, 여기서 우리는 현재 사용자 작업의 컨텍스트에 저장된 버퍼에서 문자열을 빌드하고, 그런 다음 FileDocument로 버퍼링되는 최종 저장소에서 빌드합니다. 컨텍스트는 Java Action에서만 액세스할 수 있으므로 Java에서 빌드해야 합니다.
긴 문자열을 만드는 대신 Mendix 가변 문자열, 여기서 우리는 현재 사용자 작업의 컨텍스트에 저장된 버퍼에서 문자열을 빌드하고, 그런 다음 FileDocument로 버퍼링되는 최종 저장소에서 빌드합니다. 컨텍스트는 Java Action에서만 액세스할 수 있으므로 Java에서 빌드해야 합니다.
![]() 우리가 사용하는 마이크로플로는 원본과 매우 유사하지만, 컨텍스트 메모리에 저장된 버퍼에 다음 문자열을 추가하는 Java 액션을 하나 호출하고, 완료된 문자열을 끝에 있는 FileDocument로 옮기는 Java 액션을 하나 호출합니다.
우리가 사용하는 마이크로플로는 원본과 매우 유사하지만, 컨텍스트 메모리에 저장된 버퍼에 다음 문자열을 추가하는 Java 액션을 하나 호출하고, 완료된 문자열을 끝에 있는 FileDocument로 옮기는 Java 액션을 하나 호출합니다.
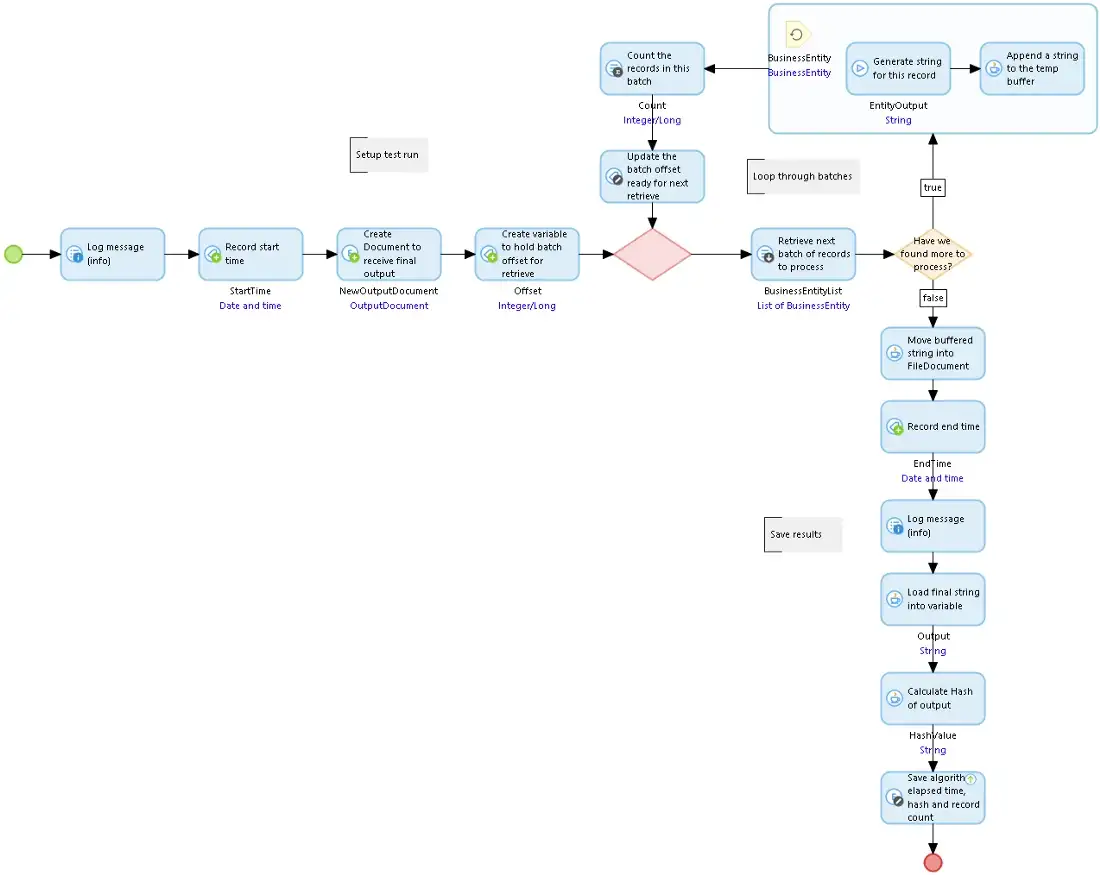 MemoryBufferBuildString 마이크로플로우
MemoryBufferBuildString 마이크로플로우![]() 두 Java 작업은 다음과 같습니다. ByteArrayOutputStream을 사용하여 데이터를 저장한 다음 이를 ByteArrayInputStream으로 변환하여 결과를 FileDocument로 이동합니다.
두 Java 작업은 다음과 같습니다. ByteArrayOutputStream을 사용하여 데이터를 저장한 다음 이를 ByteArrayInputStream으로 변환하여 결과를 FileDocument로 이동합니다.
 AppendStringToMemoryBuffer Java 작업
AppendStringToMemoryBuffer Java 작업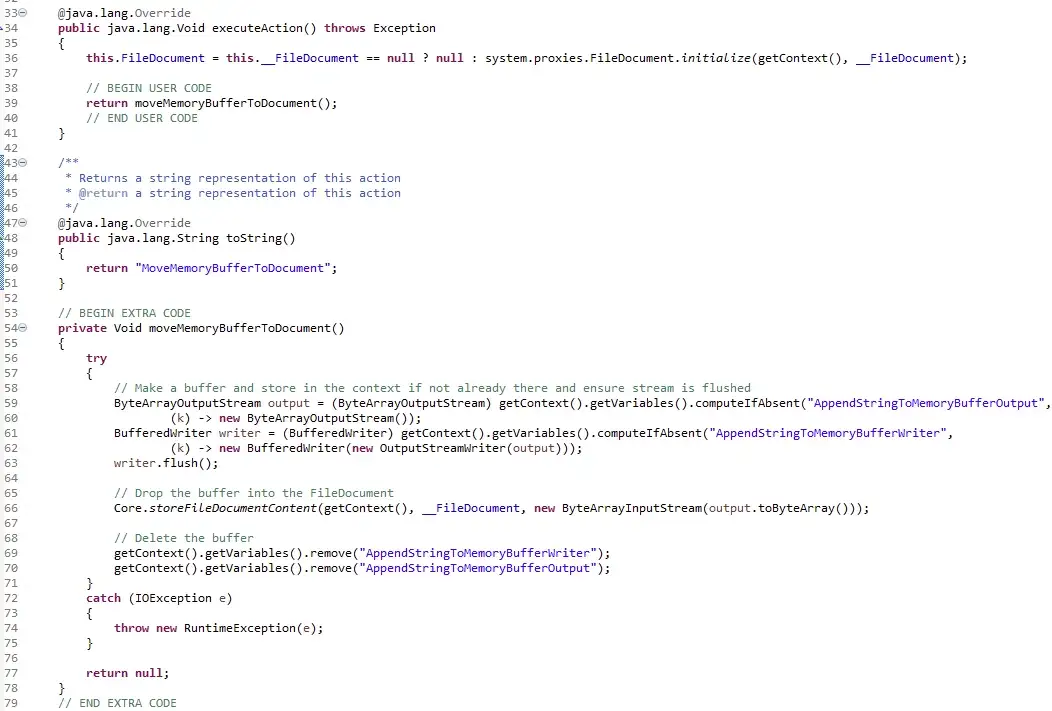 MoveMemoryBufferToDocument Java 작업
MoveMemoryBufferToDocument Java 작업그럼 이것을 실행하면 무엇이 나올까요?
![]() 글쎄
글쎄 ![]() 25,000 레코드
25,000 레코드![]() 우리는 평균을 얻는다
우리는 평균을 얻는다 ![]() 1.90 초.
1.90 초.

![]() 그리고에 대한
그리고에 대한 ![]() 50,000 레코드
50,000 레코드![]() 우리는 평균을 얻는다
우리는 평균을 얻는다 ![]() 2.94 초.
2.94 초.

![]() 원래 알고리즘(334초 대 3초)에 비해 눈에 띄는 개선이라는 데 동의하실 거라고 생각합니다. 이는 우리가 올바른 길을 가고 있다는 것을 보여주는 듯합니다.
원래 알고리즘(334초 대 3초)에 비해 눈에 띄는 개선이라는 데 동의하실 거라고 생각합니다. 이는 우리가 올바른 길을 가고 있다는 것을 보여주는 듯합니다.
![]() 하지만 이것을 더 개선할 수 있을까요? 속도는 엄청나게 향상되었지만 앱의 메모리인 버퍼에 많은 텍스트를 저장하고 있으며 결국 앱에 압력을 가할 수 있습니다. Mendix 런타임 메모리.
하지만 이것을 더 개선할 수 있을까요? 속도는 엄청나게 향상되었지만 앱의 메모리인 버퍼에 많은 텍스트를 저장하고 있으며 결국 앱에 압력을 가할 수 있습니다. Mendix 런타임 메모리.
파일 버퍼
![]() 다른 접근 방식은 잠재적인 메모리 사용 문제를 완화하면서도 원래 방식보다 더 나은 성능을 낼 수 있습니다. 이 버전의 프로세스는 생성된 텍스트를 임시 파일에 기록하므로 이를 임시 파일에 보관할 필요가 없습니다. Mendix 런타임 메모리.
다른 접근 방식은 잠재적인 메모리 사용 문제를 완화하면서도 원래 방식보다 더 나은 성능을 낼 수 있습니다. 이 버전의 프로세스는 생성된 텍스트를 임시 파일에 기록하므로 이를 임시 파일에 보관할 필요가 없습니다. Mendix 런타임 메모리.
![]() 이 옵션은 더 복잡하며 두 개의 마이크로플로와 두 개의 Java 액션을 사용해야 합니다. 첫 번째 마이크로플로는 첫 번째 Java 액션을 호출하고, 첫 번째 Java 액션은 두 번째 마이크로플로를 호출하고, 두 번째 마이크로플로는 두 번째 Java 액션을 호출합니다. 그 이유는 나중에 설명하겠습니다.
이 옵션은 더 복잡하며 두 개의 마이크로플로와 두 개의 Java 액션을 사용해야 합니다. 첫 번째 마이크로플로는 첫 번째 Java 액션을 호출하고, 첫 번째 Java 액션은 두 번째 마이크로플로를 호출하고, 두 번째 마이크로플로는 두 번째 Java 액션을 호출합니다. 그 이유는 나중에 설명하겠습니다.
![]() FileBufferBuildString 마이크로플로를 시작하려면 먼저 모든 것을 설정한 다음 BuildStringInFileBuffer Java 작업을 호출하고 마지막으로 추가 결과(해시, 레코드 수, 시간)를 Document에 저장합니다.
FileBufferBuildString 마이크로플로를 시작하려면 먼저 모든 것을 설정한 다음 BuildStringInFileBuffer Java 작업을 호출하고 마지막으로 추가 결과(해시, 레코드 수, 시간)를 Document에 저장합니다.
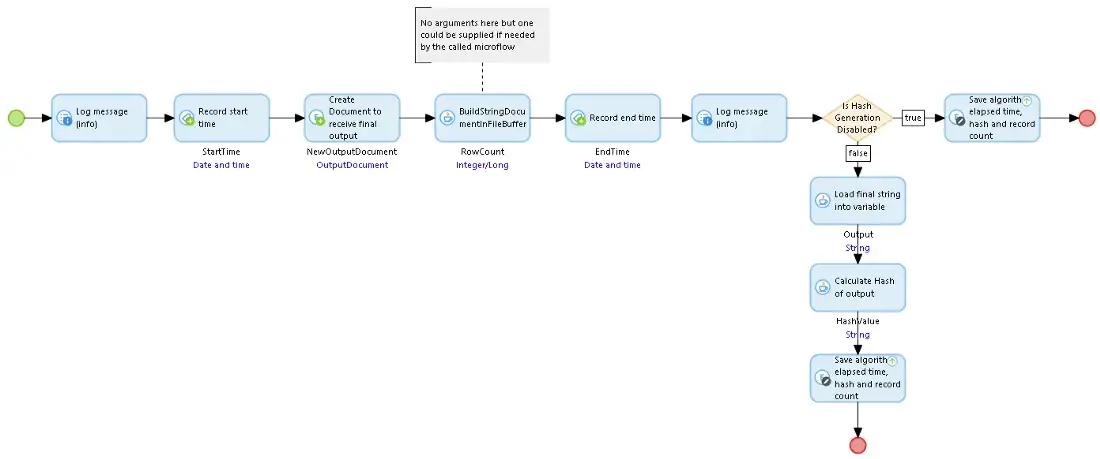 FileBufferBuildString 마이크로플로우
FileBufferBuildString 마이크로플로우![]() BuildStringDocumentInFileBuffer Java 액션은 FileDocument와 마이크로플로우 포인터(해당 마이크로플로우에 대한 선택적 인수)를 사용하여 Java 임시 파일 위치에 임시 파일을 만들고, 컨텍스트 메모리에 열린 파일 세부 정보를 저장한 다음 포인터에 지정된 마이크로플로우를 호출합니다. 해당 마이크로플로우가 반환되면 임시 파일의 내용을 FileDocument로 읽어서 정리하고 파일과 컨텍스트 객체를 삭제합니다.
BuildStringDocumentInFileBuffer Java 액션은 FileDocument와 마이크로플로우 포인터(해당 마이크로플로우에 대한 선택적 인수)를 사용하여 Java 임시 파일 위치에 임시 파일을 만들고, 컨텍스트 메모리에 열린 파일 세부 정보를 저장한 다음 포인터에 지정된 마이크로플로우를 호출합니다. 해당 마이크로플로우가 반환되면 임시 파일의 내용을 FileDocument로 읽어서 정리하고 파일과 컨텍스트 객체를 삭제합니다.
 BuildStringDocumentInFileBuffer Java 액션
BuildStringDocumentInFileBuffer Java 액션![]() SUB_FileBufferBuildString 마이크로플로는 BuildStringDocumentInFileBuffer Java 액션에 의해 호출됩니다. 레코드 배치를 읽고, 각 레코드에 대한 문자열을 생성한 다음 AppendStringToFileBuffer Java 액션을 호출하여 저장하는 루프를 실행합니다.
SUB_FileBufferBuildString 마이크로플로는 BuildStringDocumentInFileBuffer Java 액션에 의해 호출됩니다. 레코드 배치를 읽고, 각 레코드에 대한 문자열을 생성한 다음 AppendStringToFileBuffer Java 액션을 호출하여 저장하는 루프를 실행합니다.
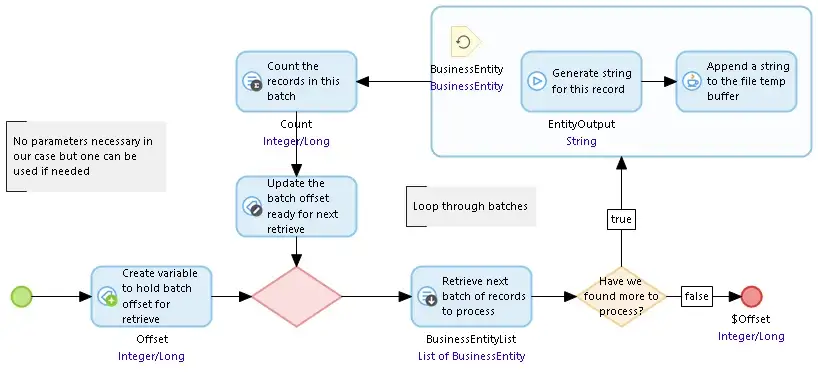 SUB_FileBufferBuildString 마이크로플로우
SUB_FileBufferBuildString 마이크로플로우![]() AppendStringtoFileBuffer Java 작업은 컨텍스트(BuildStringDocumentInFileBuffer에 의해 저장된 컨텍스트)에서 임시 파일 정보를 가져와서 단일 레코드에 대한 문자열을 임시 파일의 끝에 씁니다.
AppendStringtoFileBuffer Java 작업은 컨텍스트(BuildStringDocumentInFileBuffer에 의해 저장된 컨텍스트)에서 임시 파일 정보를 가져와서 단일 레코드에 대한 문자열을 임시 파일의 끝에 씁니다.
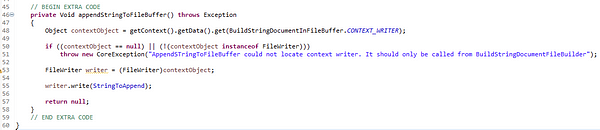 AppendStringToFileBuffer Java 작업
AppendStringToFileBuffer Java 작업![]() 좋아요, 그럼 이 배열은 (
좋아요, 그럼 이 배열은 (![]() 마이크로플로우-호출-자바-호출-마이크로플로우-호출-자바
마이크로플로우-호출-자바-호출-마이크로플로우-호출-자바![]() )는 약간 복잡하고 모호하다고 간주될 수 있으며 내가 이전 블로그 게시물(가독성 대 유지 관리성)에서 말한 것과 상충될 수 있습니다.
)는 약간 복잡하고 모호하다고 간주될 수 있으며 내가 이전 블로그 게시물(가독성 대 유지 관리성)에서 말한 것과 상충될 수 있습니다. ![]() 그래서 나중에 개발자들을 위해 잘 문서화되어야 합니다..
그래서 나중에 개발자들을 위해 잘 문서화되어야 합니다..
![]() 이 접근 방식에는 한 가지 좋은 이유가 있습니다. 안전하기 때문입니다. 프로세스에서 문제가 발생하면 첫 번째 Java 작업에서 임시 파일과 열린 파일 설명자를 정리한 다음 첫 번째 마이크로플로로 돌아갈 수 있으므로 앱 전체가 손상될 가능성이 줄어듭니다. 이 블로그와 함께 제공되는 앱에는 대안이 있습니다(TempStorage라고 함). 참조
이 접근 방식에는 한 가지 좋은 이유가 있습니다. 안전하기 때문입니다. 프로세스에서 문제가 발생하면 첫 번째 Java 작업에서 임시 파일과 열린 파일 설명자를 정리한 다음 첫 번째 마이크로플로로 돌아갈 수 있으므로 앱 전체가 손상될 가능성이 줄어듭니다. 이 블로그와 함께 제공되는 앱에는 대안이 있습니다(TempStorage라고 함). 참조 ![]() GitHub에서 문자열의 길이는 얼마인가 -
GitHub에서 문자열의 길이는 얼마인가 - ![]() 마이크로플로와 Java 액션의 중첩을 사용하지 않지만, 문제가 발생할 경우 호출자가 정리하는 데 훨씬 더 주의해야 합니다.
마이크로플로와 Java 액션의 중첩을 사용하지 않지만, 문제가 발생할 경우 호출자가 정리하는 데 훨씬 더 주의해야 합니다.
![]() 그렇다면 결과는 무엇입니까?
그렇다면 결과는 무엇입니까? ![]() 25,000 레코드
25,000 레코드![]() 걸렸다 1.23
걸렸다 1.23![]() 초, 그리고
초, 그리고 ![]() 50,000 레코드
50,000 레코드![]() 걸렸다
걸렸다 ![]() 2.75 초.
2.75 초.


![]() 메모리 버퍼
메모리 버퍼![]() 그리고
그리고 ![]() 파일 버퍼
파일 버퍼 ![]() 성능은 매우 비슷하지만 이제 원본을 볼 수 있습니다.
성능은 매우 비슷하지만 이제 원본을 볼 수 있습니다. ![]() 출발점
출발점![]() 알고리즘은 세 가지 중에서 가장 성능이 떨어지며, 이 연습의 목적을 위해 더 이상 사용할 필요가 없습니다. 다른 두 가지 중에서 선택할 수 있습니까?
알고리즘은 세 가지 중에서 가장 성능이 떨어지며, 이 연습의 목적을 위해 더 이상 사용할 필요가 없습니다. 다른 두 가지 중에서 선택할 수 있습니까?
플레이 오프
![]() 이러한 솔루션을 비교할 때 메모리 사용량을 또 다른 요소로 언급했으므로 이에 대한 통계도 얻어야 합니다. 명확성을 높이기 위해 더 큰 샘플의 테스트 데이터를 사용하겠습니다.
이러한 솔루션을 비교할 때 메모리 사용량을 또 다른 요소로 언급했으므로 이에 대한 통계도 얻어야 합니다. 명확성을 높이기 위해 더 큰 샘플의 테스트 데이터를 사용하겠습니다. ![]() 500,000 레코드.
500,000 레코드.
![]() 인구가 설정되고 앱이 다시 시작되었고
인구가 설정되고 앱이 다시 시작되었고 ![]() 메모리 버퍼
메모리 버퍼 ![]() 프로세스가 한 번 실행되었습니다.
프로세스가 한 번 실행되었습니다. ![]() 그라 파나
그라 파나![]() 이 프라이빗 클라우드에 설정하면 리소스 사용에 대한 정보를 얻을 수 있습니다.
이 프라이빗 클라우드에 설정하면 리소스 사용에 대한 정보를 얻을 수 있습니다.
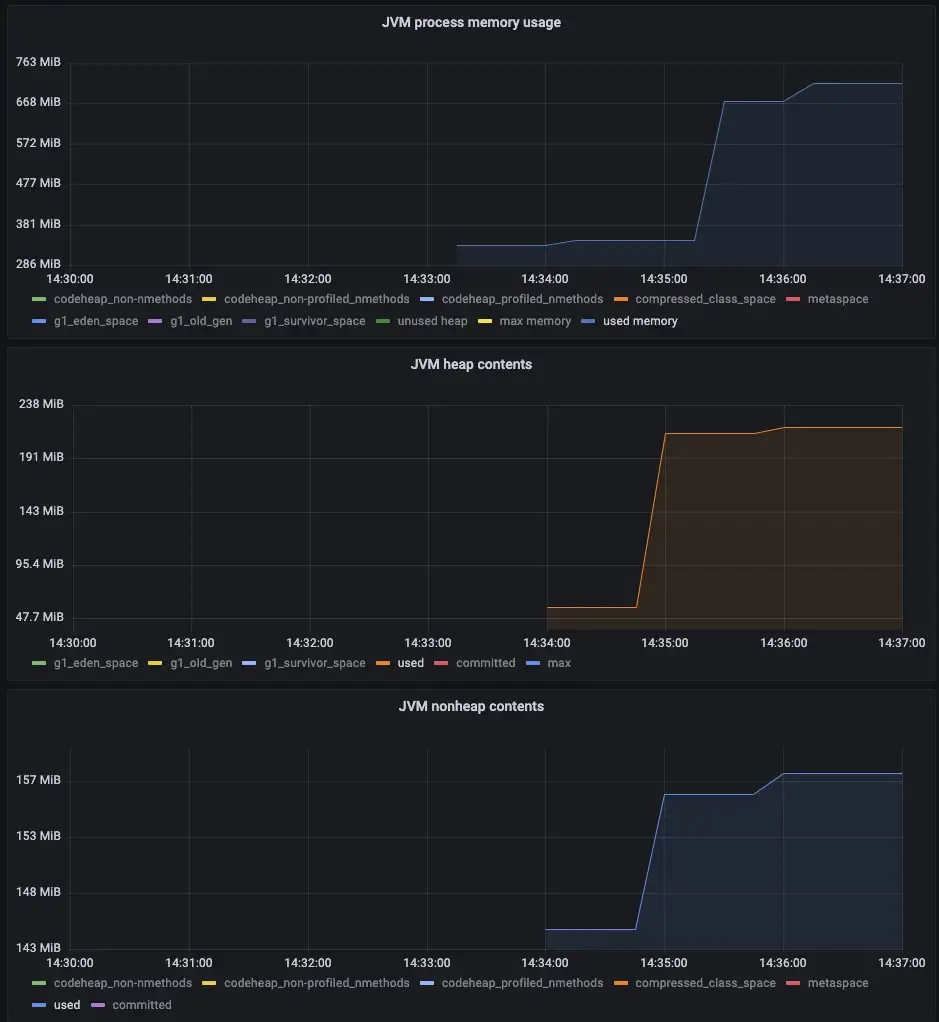
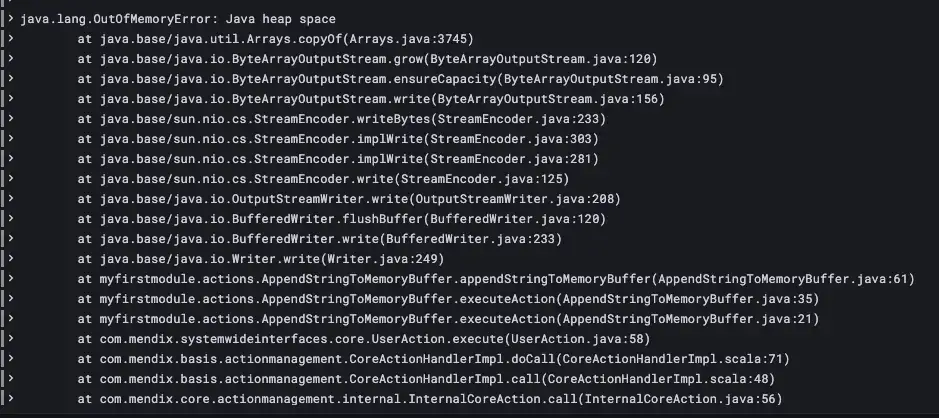
![]() 아야!
아야! ![]() 메모리 버퍼
메모리 버퍼 ![]() 충분히 강하지 않다
충분히 강하지 않다![]() 이 작업 크기를 처리하고 AppendStringToMemoryBuffer에서 버퍼를 채우는 동안 앱의 메모리가 소진되었습니다.
이 작업 크기를 처리하고 AppendStringToMemoryBuffer에서 버퍼를 채우는 동안 앱의 메모리가 소진되었습니다. ![]() 파일 버퍼
파일 버퍼 ![]() 더 잘 하세요? 앱이 다시 시작되었고
더 잘 하세요? 앱이 다시 시작되었고 ![]() 파일 버퍼
파일 버퍼![]() 실행되었습니다:
실행되었습니다:
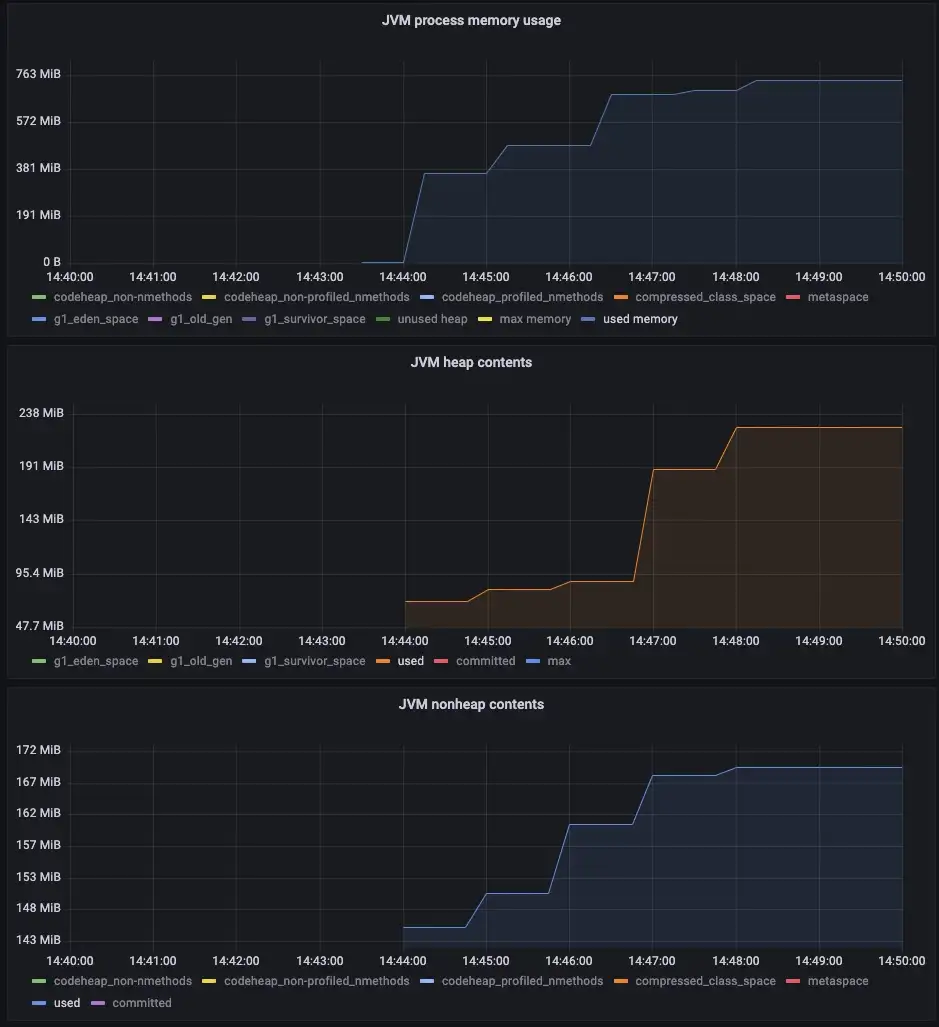
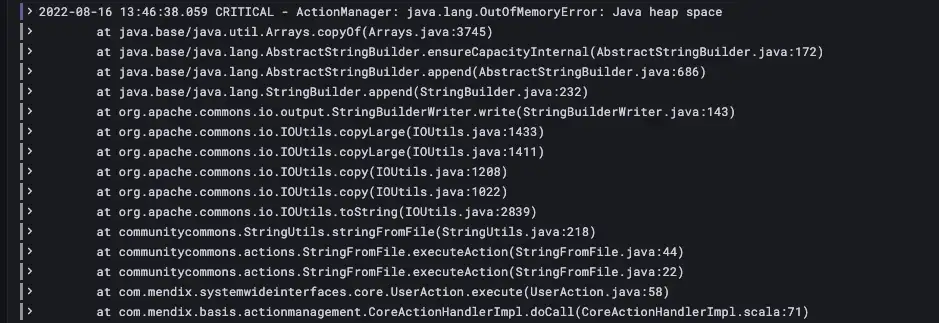
![]() 잠깐! 그러니까
잠깐! 그러니까 ![]() 파일 버퍼
파일 버퍼![]() 또한 실패했지만 Out of Memory로 인해 사망했습니다.
또한 실패했지만 Out of Memory로 인해 사망했습니다. ![]() 시간 내에
시간 내에![]() FileDocument가 성공적으로 생성되고 채워졌으며 생성된 전체 파일을 읽어서 데이터의 해시 값을 계산하는 프로세스 중에 문자열(CommunityCommons StringFromFile)로 변환했습니다. 파일이 너무 커서 그럴 수 없습니다. 그래서 문자열을 읽고 해시 작업을 호출하는 코드(상수 사용)를 비활성화하고 프로세스를 다시 실행했더니 작동했습니다.
FileDocument가 성공적으로 생성되고 채워졌으며 생성된 전체 파일을 읽어서 데이터의 해시 값을 계산하는 프로세스 중에 문자열(CommunityCommons StringFromFile)로 변환했습니다. 파일이 너무 커서 그럴 수 없습니다. 그래서 문자열을 읽고 해시 작업을 호출하는 코드(상수 사용)를 비활성화하고 프로세스를 다시 실행했더니 작동했습니다.

![]() 네, 완료되었고 우승자가 나온 것 같습니다!
네, 완료되었고 우승자가 나온 것 같습니다!
![]() 좋은 조치를 위해 나는 다음을 설정했습니다.
좋은 조치를 위해 나는 다음을 설정했습니다. ![]() 1,000,000 레코드
1,000,000 레코드![]() 데이터 집합과 실행
데이터 집합과 실행 ![]() 파일 버퍼
파일 버퍼 ![]() 다시 이것 역시 완료되었습니다.
다시 이것 역시 완료되었습니다.

마일리지는 다를 수 있습니다
![]() 물론 이 모든 것이 실제 상황에서 어떻게 수행되는지는 이 글의 범위를 벗어나는 많은 요인에 따라 달라지겠지만, 이 글이 예외적인 상황에서 문자열 생성의 탄력성과 성능을 개선하는 방법을 보여주는 데 유용했기를 바랍니다. 또한 Java를 일반적으로 사용하여 성능을 높이는 데 어떻게 도움이 될 수 있는지도 보여주었습니다.
물론 이 모든 것이 실제 상황에서 어떻게 수행되는지는 이 글의 범위를 벗어나는 많은 요인에 따라 달라지겠지만, 이 글이 예외적인 상황에서 문자열 생성의 탄력성과 성능을 개선하는 방법을 보여주는 데 유용했기를 바랍니다. 또한 Java를 일반적으로 사용하여 성능을 높이는 데 어떻게 도움이 될 수 있는지도 보여주었습니다.
![]() 다음 Efficiency 게시물에서는 내장된 기능을 사용하여 긴 작업이 어떻게 개선될 수 있는지 보여드릴 계획입니다. Mendix 작업 대기열 기능.
다음 Efficiency 게시물에서는 내장된 기능을 사용하여 긴 작업이 어떻게 개선될 수 있는지 보여드릴 계획입니다. Mendix 작업 대기열 기능.
감사의
![]() 귀중한 조언을 해준 Arjen Wisse와 이 글의 맨 위에 언급된 멋진 CSV 모듈을 알려준 Arjen Lammers에게 감사드립니다. 저는 부끄러움 없이 그 모듈에서 아이디어를 빌렸습니다.
귀중한 조언을 해준 Arjen Wisse와 이 글의 맨 위에 언급된 멋진 CSV 모듈을 알려준 Arjen Lammers에게 감사드립니다. 저는 부끄러움 없이 그 모듈에서 아이디어를 빌렸습니다.