This is a guest blog by David de Groot – Mendix Consultant at Sogeti
In the second part of this two-part blog I describe another advanced branching and merging strategy for complex operational environments. This strategy is based on my personal experience at current and past clients with (multiple) projects and ongoing parallel maintenance. Due to the experienced limitations of the first strategy (described in part 1), we had to adapt and come up with a more flexible way of working. That lead to the second advanced strategy.
In this blog I will give a short description of the first strategy. Following that, I will explain the second advanced strategy for branching and merging that adheres to the principle of “No junk in the trunk”. This second blog concludes the series of blogs on advanced branching and merging strategies. A good understanding and experience with the basics of branching and merging, Subversion (SVN), and Mendix is required to understand what is described here. I assume that the audience is familiar with the concepts as described on the Mendix documentation on Version Control Concepts.
Recap on Strategy 1: Maintenance and Projects
In my previous blog I presented a first strategy that adheres to the “No junk in the trunk” principle that is suitable for complex operational environments with maintenance and projects happening in parallel. To summarize, the principle requires:
- That all development takes place in branch lines (and never on the Main Line)
- The Main Line is the general starting point for new branch lines
- Only fully tested changes are merged to the Main Line
- After a merge to Main Line, a merge-back to all active branch lines is needed. Also a merge-back to the source-branch line if development on the branch line is continued. This is needed to make sure that all branch lines stay in sync.
Application of the above bullet points for the principle “No junk in the trunk” led us to strategy 1, where these branch lines can be distinguished:
- Main Line
- Maintenance branch line, called, for example, Maintenance or Business As Usual (BAU)
- Optionally a project/feature development branch line
- Additionally, there can be hotfix branch lines for a small production patch
In this strategy, all changes are only done in the branch lines and will be merged to Main Line after they have been tested. Testing is done on a package that is generated from the respective branch line. After testing is completed successfully, changes are merged to Main Line. After that, those commits have to be merged-back to all the active branch lines to keep everything in sync. A production deployment is usually done from a versioned package from the Main Line and sometimes done from a tested hotfix-line.
We have been following the strategy for over a year, and found that is generally works well. It is a good step forward to being in control of changes and versions, however, this strategy does provide a number of challenges:
- Changes for features and fixes often stack up in one development branch line and result in an all-or-nothing package deal. If commits are not clearly described and/or are mixed (or depend on each other) the changes cannot be isolated and left out at a later point. (See also the explanation below on ‘How do changes get tied-up?’)
- Preparation for a production release with a merge to the Main Line can be time-consuming This turned out to become a major obstacle at my current client: a very tight release schedule, a short window, and last moment Go/No Go decisions with testing going on until the very last moment, made holding on to this strategy impossible.
- Merge-backs can be time-consuming as well. This is less of a drawback as this usually doesn’t have any time-pressure on it.
- Combining branch lines, for example for deployment in a test environment, is difficult, and sometimes even impossible: testing on multiple branch lines is impossible if kept strictly to those branch lines. One possibility is to use an un-versioned package based on a local merge. Another possibility is to introduce deployment branch lines, a first step in the direction of the next strategy. Either way, there may be conflicts to resolve, which is a challenge in itself to resolve and often takes a lot of time.
How Do Changes Get Tied Up?
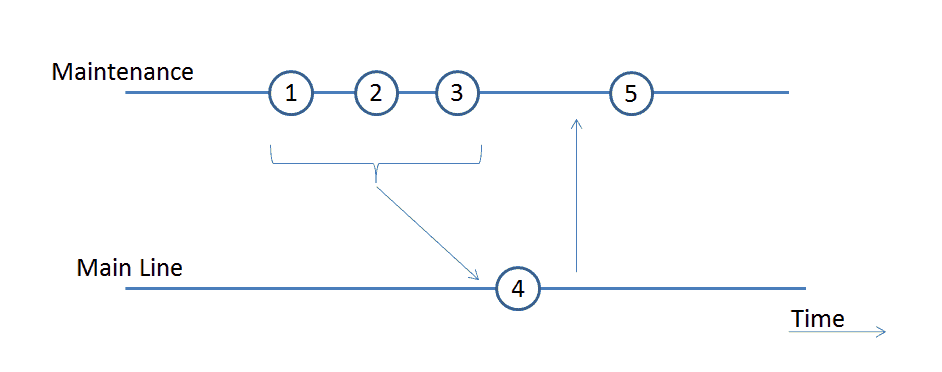
In the ideal situation, every commit is clearly recognizable as belonging to a certain change and no mixing takes place. See also the illustration below.
Here, two branches are shown as horizontal lines and time running from left to right. Each committed change on the line is depicted as a circle/oval. In due time, three changes were done on the Maintenance branch line. Then they were tested based on a package generated from that line. After the tests were completed, the changes were merged to the Main Line (merges are shown as arrows) and then merged-back to the Maintenance and the Project branch lines (only the merge back to the Maintenance branch line is depicted).
Assuming there are no dependencies between the changes, each of them can be excluded from the merge and included at a later point.
However, reality is different: changes are often not committed separately, may depend on each other and therefore cannot be isolated anymore, and cannot be delivered separately. For example, consider this simple scenario, as illustrated below: changes for request 1 were made first. As 2 and 3 were small changes, the developer did it quickly and committed them together.
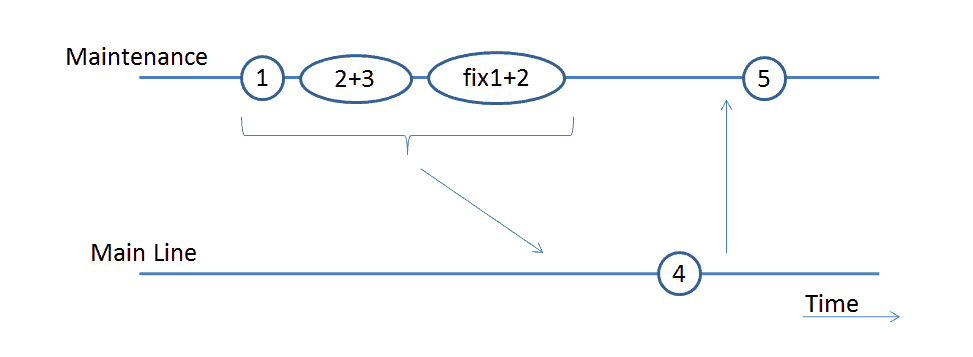
However, during testing they discovered that something was not quite right, and a fix was done for 1 and 2 together in a single commit. This ties all the changes to each other and effectively turns the release into an all-or-nothing package-deal.
All in all, because of this and the other reasons mentioned earlier, we started to change the way we worked, and no longer followed Strategy 1 for maintenance and projects. First, we had added temporary deployment branch lines, then more and more changes and problems got their own branch line. Finally, we stopped updating the continuous Maintenance branch line, which cause us to end up working with Strategy 2 that is described next.
Strategy 2: Mendix Flow
In this strategy, each set of changes gets their own branch line: each project and feature request (or bug fix, problem ticket, or whatever else you may have) commits their changes to their own development branch line.
When the change is ready for testing, the development revisions get merged to a deployment branch. Currently, at my client, we keep one deployment branch for quality and another one for the acceptance environment each month. Note that deployments are now done only from deployment/staging branch lines, never from the Main Line.
A rollout to the production environment is done using the tested package from the acceptance environment once the features are fully tested and accepted. After the cooldown period of three working days, the revisions get merged to the Main Line if no major incidents took place. Changes to the Main Line are then merged-back to the active development branch lines.
We now have these branches:
- Main Line
- (Multiple) development branch lines: for every bug fix, feature, or other change
- Hotfix branch lines
- Project branch lines
- Deployment/staging branch line(s)
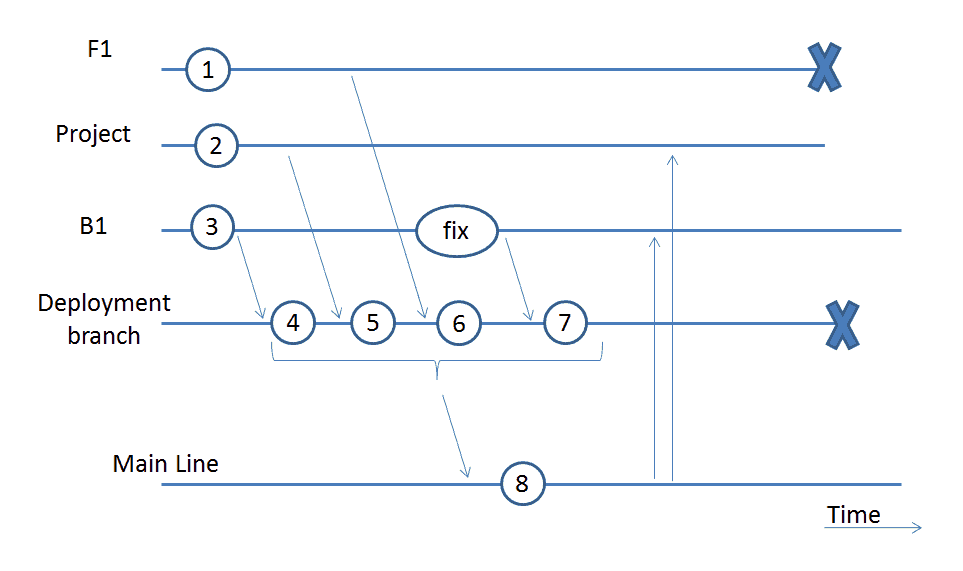
Note that in this strategy we don’t have a continuous maintenance branch line anymore. It is an option to keep it, but not strictly necessary, since all the changes are done in their own branch lines. See also the illustration below, where you see the branch lines for a feature branch F1, a long running Project bug fix branch line B1, and the Main Line.
Again, branches are shown as horizontal lines and time running from left to right. Each committed change on the line is depicted as a circle/oval. The merges and merge-backs are shown as arrows.
Here, changes 1, 2 and 3 are each developed in their own branch lines. Also, the fixes for those changes need to be done in their own branch line, and everything is merged to the deployment branch line (with each set of changes having their own commit) to be deployed and tested. Go-live can be done using the tested package from the deployment branch.
The final wrap-up with merging to the Main Line is done after the go-live and after the cooldown period. Merges back from Main Line to active branch lines is the last action needed to have everything in sync again. When all the merges are done, both the feature branch line and the deployment branch line can be terminated (“X” in the illustration).
For how to do the merges and the management of the branch lines I refer back to part 1 of this blog series, and to the documentation on Version Control Concepts as provided by Mendix.
Pros And Cons
The big pro is that this approach allows more flexibility, for example to exclude a certain change if not approved by (business) tests. It also allows for more parallel development and multiple teams. Additionally, it allows for preparation of the release in a timely manner, as the deployment package is generated from the Deployment branch line. The package is then deployed and tested and gets promoted to the production environment. This allows for more control and assures quality of the delivered changes.
On the downside, this strategy can be complex, time consuming and intense. Indeed, there can be a lot of branch lines that ask for tight branch-management by one or two people who keep a list and keep track of the status of each branch line. It also requires meaningful, consistent naming of the branch lines and what’s in them. As before, merges and merge-backs can be a pain and can still be a lot of work.
Conclusion
To conclude, let’s review the applicability of this second strategy, and take a look at the lessons learned in the time that we have been using it.
Applicability
The strategy described above is specifically useful in the following situations:
- Multi-team maintenance environments with projects
- Agile/scrum development
- Releases with multiple features and fixes
- High risk versus low risk change tracks
- Any situation with a need for flexibility and multiple changes under (parallel) development. For example, when one change is not approved or tests failed but others are promoted.
Lessons Learned
- Commit with informative descriptions, use a reference number whenever applicable
- Make small commits, commit often, and don’t mix multiple features in one commit
- More branch lines allow for more flexibility
- Think about dependencies of changes before starting (those need to be done in the same branch line or scheduled after each other)
- Deploy from multi-merge deployment/staging branch lines, not from the Main Line
- Use separate branch lines for different changes or different issues
- Keep a good overview of your branch lines, name them so you can easily recognize them. Use a naming convention such as the type of issue (change, problem or incident), the date, or ticket number and keywords, or a short description, for example, resulting in the branch line name PRB160215_YA02_MultimaterialCreate)
- Clean up the dead branch lines regularly (good old-fashioned pruning)
All that said, the first and foremost principle to follow is this: have fun, do the changes and make a difference! Happy developing!
Thanks
Thanks to Richard for planting the seeds and getting me to think about improving branching and merging and also pushing me to keep improving. Thanks to Reinout, my Sogeti colleagues Edzo and Louis, and the Mendix reviewers for giving constructive comments. The end result wouldn’t have been the same without them.
About David de Groot
Now working at Sogeti for three years, David has a been working with Mendix for over 6 years and is a certified Advanced Developer. He has been working at various Dutch and international companies, mainly as consultant in maintenance and support, though intermittently also involved in projects and new builds. David has a background in Oracle and PL/SQL development and holds a Master of Science degree in Artificial Intelligence.
References
Version Control Concepts in the Mendix Documentation
“Version Control for Multiple Agile Teams“,
GIT Branch / Merge Strategy (No Junk In The Trunk)
A successful Git branching model, Vincent Driessen, 2010
Version Control with Subversion
- http://svnbook.red-bean.com/ E.g. http://svnbook.red-bean.com/en/1.7/svn.branchmerge.commonpatterns.html
InfoQ Book: Scrum and XP from the Trenches