Health and Efficiency in Mendix
All apps can be inefficient and that includes Mendix apps. Inefficiencies may be almost invisible during development and only appear as issues when the app enters volume or stress-testing. However, it is true that common patterns can be identified during development and improvements made immediately.
In this short series, I want to cover a few of the simple — and not-so-simple — ways that Mendix apps can be made to be more efficient. The ideal result should be an app that performs its job in the least time possible and consumes the fewest resources possible.
Always?
No.
Sometimes, there is a trade-off between an option that is readable and maintainable or a more highly optimized version that may be ingenious, and more efficient but difficult to understand and which will be an issue for you or another developer having to maintain the code in the future.

That’s a judgment call to be made by the team at the time the development is in progress, or when a performance issue is being investigated, and it may be that good quality comments or documentation will help in promoting understanding of unclear code.
Also, the more often something runs, the greater the likely benefit from improving its efficiency. An action that could be optimised to take 5 minutes instead of 10 but is only run once a month probably should be less of a focus when looking for efficiency gains, whereas a half second efficiency gain in an action that runs thousands of times a day is certainly a higher priority.
Golden Oldies
Some patterns of design within Mendix have been highlighted before, but are worth visiting again as sometimes they are missed by new and seasoned developers alike.
Loop De Loop

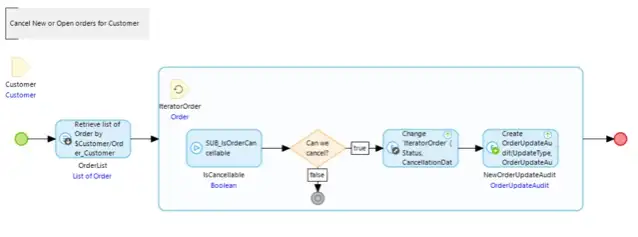
When using a loop to create or modify objects in a microflow collect the new/modified objects of the same type in a list and commit that list outside the loop.
Instead of:
You can use:
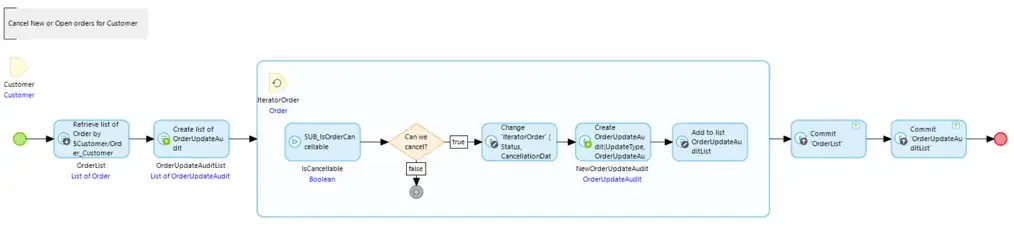
This will mean that there is a single commit for Order objects and another for OrderUpdateAudit objects being used at the end of the process for the new and changed objects. Commits can be expensive as each one requires your app to run a round trip to the database and each round trip carries an overhead, so batching the commits together reduces the number of round trips and therefore the overhead.
Let Your Aggregates Fly!
The Mendix runtime goes too long lengths to optimize the database queries resulting from the low code you write, for example in your microflows you can place a list aggregate activity immediately following a retrieve activity:
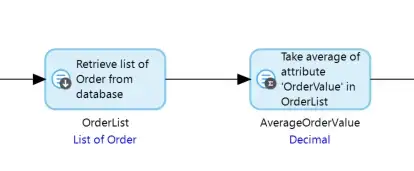
This causes the runtime to execute a single statement against the database which will calculate the average value of the OrderValue on Order. The Order records will not be retrieved into the app at all and OrderList will not actually be produced. This will make the execution faster.
However, it’s possible to break this optimization by re-using the generated list afterward.
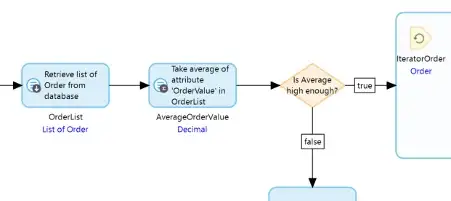
Now the OrderList is being used again after the aggregate has been run (as the data source for the IteratorOrder loop) and this means that Mendix reverts to standard behaviour and executes the Retrieve to load all the records into OrderList and then calculates the average by scanning down the records in that list.
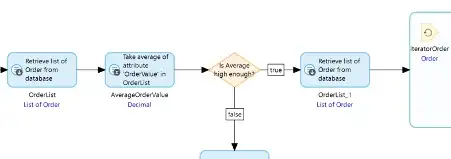
In these circumstances, it may well be faster to run the Retrieve activity twice — once for the aggregate to use and once again to get the record list. This is particularly applicable in this illustration as the second Retrieve, (which is now the source for the IteratorOrder loop), is only run if the calculated average is adequate so if the average is low then the list is not retrieved at all.
Using Nanoflows instead of Microflows

Microflows are powerful code actions that are executed on the Mendix server, frequently instigated by the user’s Mendix Client. Nanoflows can perform a lot of the same activities as Microflows, though in some cases the way they work varies from the way that Microflows work. The big difference is that a Nanoflow runs in the Mendix Client (the user’s browser or native app) which can give a Nanoflow a big efficiency advantage over a Microflow performing a similar function.
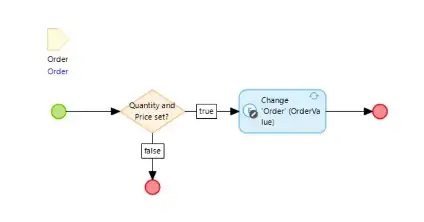
This Microflow is called from a button on the User Interface and implements a business rule that may update the object being displayed. Clicking the button causes a call to be made from the Mendix Client back to the app on the server asking for the Microflow to be run and the results to be returned to the Client.
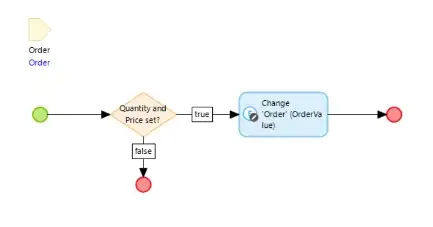
This Nanoflow does the same thing. Functionally it is almost identical to the Microflow, but the whole operation executes in the User’s Mendix Client so that the call from the Client to the server, the execution of the code on the server, and the return of the results to the Client does not happen. This reduces network traffic and avoids the server from being interrupted to perform the changes for the User.
The use of Nanoflows is not always a good idea. If your Nanoflow needs to call a Microflow as part of its function, then you may not save yourself anything as there will still be the network interaction and server interrupt happening. If your Nanoflow needs to call multiple microflows or needs to retrieve further data from the database to perform its function, then it is probable that using a Nanoflow instead of a Microflow will be counterproductive.