Many of the Mendix 7 features announced during Mendix World 2016 have been rolled out in recent months. In this blog post we’ll highlight one of the most significant changes in this month’s release: the new Mendix Runtime.
There is one part of Mendix 7 that we didn’t talk about much during Mendix World 2016: moving Mendix Runtime to a completely new stateless architecture. This month we released Mendix 7.0, a release that improves the scalability and availability of your Mendix applications considerably. Mendix 7.0 also contains important steps to improve the extensibility of the Mendix Platform through Java actions, modules, and the Connector Kit.
This article provides an overview of these scalability and extensibility improvements. For a complete overview of all the improvements in this release you can consult the release notes.
Stateless Runtime
Mendix has always supported high availability and scalability through different means. Last year Mendix 6 introduced a state-database to share state among multiple runtime instances. This enabled seamless failover and distribution of requests across a number of runtime instances.
Mendix 7 introduces the next generation of scalability and availability: to improve performance and to support seamless distribution of requests among multiple runtimes for complex applications the Mendix Runtime is now completely stateless. This means that, between requests, data will either be stored in the database or in the client (mobile app or browser), but no longer in the Mendix Runtime.
How Does This Work?
The big architectural improvement in Mendix 7 is that the runtime no longer keeps track of what data a user is working on. Instead, the Mendix Client keeps track of all this information. As soon as a request to the runtime has finished and the relevant data has been either stored in the database or sent to the client, the runtime will clean up all state in the runtime. Unsaved changes will be sent to the client and provided by the client to the runtime for any subsequent request.
This has a number of benefits for your Mendix applications:
- The client sends data relevant for the request to the runtime. This means the runtime immediately has the relevant data and doesn’t need to get it from a separate state database. This also limits the amount of state that the runtime will need to handle the request. To optimize the size of your request the Mendix Platform analyzes your application model to determine what data is required by your application.
- Garbage collection can be done more effectively: the client, browser or mobile app, knows exactly what data is still required for the pages available to the user. As soon as data is no longer needed, it can be removed in the client. At the other end, the runtime can always remove all data after a request. This means that you will see reduced memory requirements for your runtime instances.
- No complex server-side coordination is needed to provide high availability and scalability: a client request can be handled by any runtime without any coordinated state or logic. The browser provides all the context required to handle a browser request. For failover this means that nothing special needs to be implemented as long as some runtime instances are available to handle a request, the browser can be served a response. Similarly, for scalability, adding more runtime instances the handle more users, basically just means adding more runtime instances. All user requests can now be handled by the larger pool of runtime instances.
Cloud Support
Another benefit of the Mendix 7 approach is the reduced infrastructure complexity: a state database is no longer required because state is now maintained by the Mendix client. Mendix 6 required a state database, either the application database, or Redis.
Removing this requirement simplifies installation and maintenance, which makes it easier to deploy Mendix in all the different Clouds that we support. The availability and scalability benefits of stateless Mendix Runtime are available in all deployment scenarios, including public Cloud Foundry Platforms like Bluemix and Pivotal. You will also be able to use this with our deployment support on Azure and AWS.
And finally, in the Mendix Cloud you’ll be able to use this feature to enable horizontal scalability by simply dragging a slider to increase the number of runtimes you allocate for your app.
Migration
For most developers, building highly available and scalable applications means that have to take special considerations with their code. Mendix removes this effort from the developers. We have taken considerable effort to make migration as easy as possible. Stateless runtime has minimal impact on most Mendix models.
The most important change you will notice is that you can no longer have attributes on non-persistent entities without read or write privileges. The reason for this is simple: non-persistent entities are not stored in the database. This means that the client must keep track of these objects. However, that also means sending this data to the client, thereby making the data available to the client, which requires read privileges. The migration guide explains how to improve your application model in case you run into this situation.
Monitoring
As mentioned before, the client sends all relevant data to the runtime. To help you build efficient scalable applications we’ve added information to the runtime logs to inform you about the size of the state needed for every request. You will also see warnings in case a large amount of state is used. You can use this to optimize your Mendix application models. For more information, see the migration guide.
For example, the following log message reports that a total of four objects are included in the request from browser to runtime. It also specifies the respective entities involved.
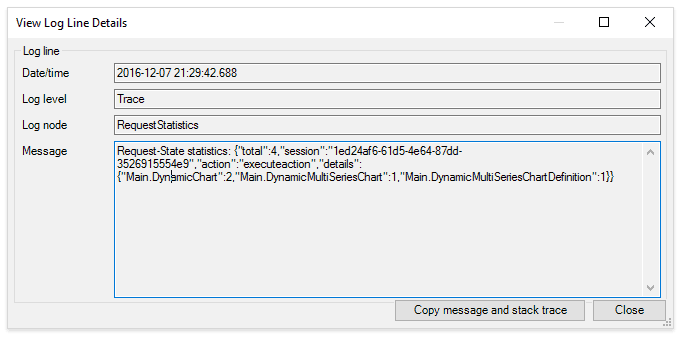
Developer Tooling
To help you develop efficient applications, we’ve also included developer support in the client. You can use the default developer tooling of your web browser to inspect communication of objects between client and server. Additionally, we also provide information about objects available in client state. This should especially help JavaScript developers to write robust custom widgets.
Extensibility
Extensibility is an important aspect of any platform. Especially these days when you need to integrate with a large number of existing products and services. The Mendix philosophy is to enable you to easily extend the platform so you’re never limited by it. Whether it’s the client that you can extend with JavaScript widgets or the runtime where you can create java actions or provide entire modules through the Mendix App Store.
 During Mendix World 2016 we launched the Mendix Connector Kit, which adds a whole new layer of robustness and user-friendliness on top of custom Java actions. By providing Java actions in the default Modeler toolbox, users no longer see a difference between native Microflow actions and custom Java actions. Additionally, a number of new parameter types have been introduced to make these microflow actions easier to use. In recent months we’ve introduced entity and microflow parameters.
During Mendix World 2016 we launched the Mendix Connector Kit, which adds a whole new layer of robustness and user-friendliness on top of custom Java actions. By providing Java actions in the default Modeler toolbox, users no longer see a difference between native Microflow actions and custom Java actions. Additionally, a number of new parameter types have been introduced to make these microflow actions easier to use. In recent months we’ve introduced entity and microflow parameters.
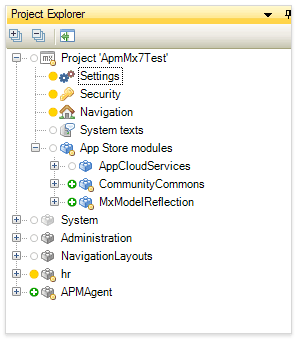
To improve usability, in Mendix 7 we’ve grouped the App Store modules in a separate node in the Project Explorer. This allows you to focus on the business functionality in your projects, because your projects are no longer complicated by a large number of App Store modules.
This month’s release includes some large improvements under-the-hood. The Mendix API used by Connector Kit Java actions has been cleaned up, and made explicit. This ensures that you can rely on the backwards compatibility of these APIs, and be ensured of easy upgrades. For Mendix 7 however, this means that when you upgrade your application, you may need to upgrade your modules, or you may have to modify some of your API calls. Please consult the upgrade guide for more detailed information.
REST
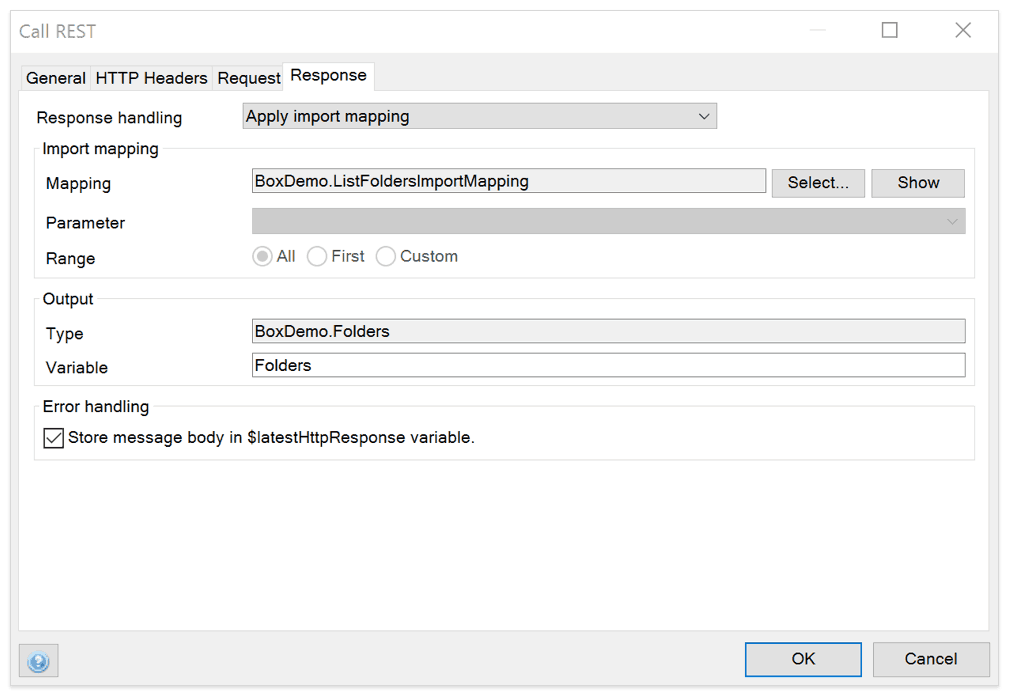
To finish this blog post I’d like to mention some new REST features. Since the initial public release of native REST support in the Mendix Modeler, we’ve regularly added new functionality in monthly releases. Mendix 7.0. includes easy access to the entire HTTP response, including status code, status message, headers, cookies and if needed the raw payload. This will enable you to quickly implement custom authentication schemes or handle specific status codes using some microflow actions.
Summary
Building highly scalable, high available applications that easily integrate with all the existing services that you need has never been easier!