In Mendix how long is a String?

This is the second in my series of blogs about efficiency in Mendix apps. In the first of the series (Health and Efficiency in Mendix), I highlighted some of the simple ways that you might improve the efficiency of your low-code. Now I’ll try to tackle something tougher.
Twice in the last five years, I have had to deal with requirements that essentially said: go through all this data and build a text file from it.
The first was to produce a tab-separated text file representing a set of data in the Mendix app. The second required the creation of a Typescript file from a set of data that had been built in the app. Both of these needed to support the creation of very long text files as the sets of data could be pretty big.
Nowadays there are great modules in the Marketplace (for example the CSV Module) that can help with CSV/TSV file production, but more arbitrary text output needs an alternate solution.

Test Exercises
To gather statistics for comparison I’m using an app created in Mendix 9.15.1, deployed on a Medium size environment (max 2 CPUs, max 2GB memory, Postgres database) running in an AWS EKS Private Mendix Cloud which includes Grafana monitoring.
Each exercise is run five times. Before each set of five exercises is run the app is stopped and started to minimize possible caching influences on the results. The best and worse results are discarded and the other three are averaged. The exercises are not necessarily run in the order presented here.
The app used is available on GitHub here.
The Starting Point
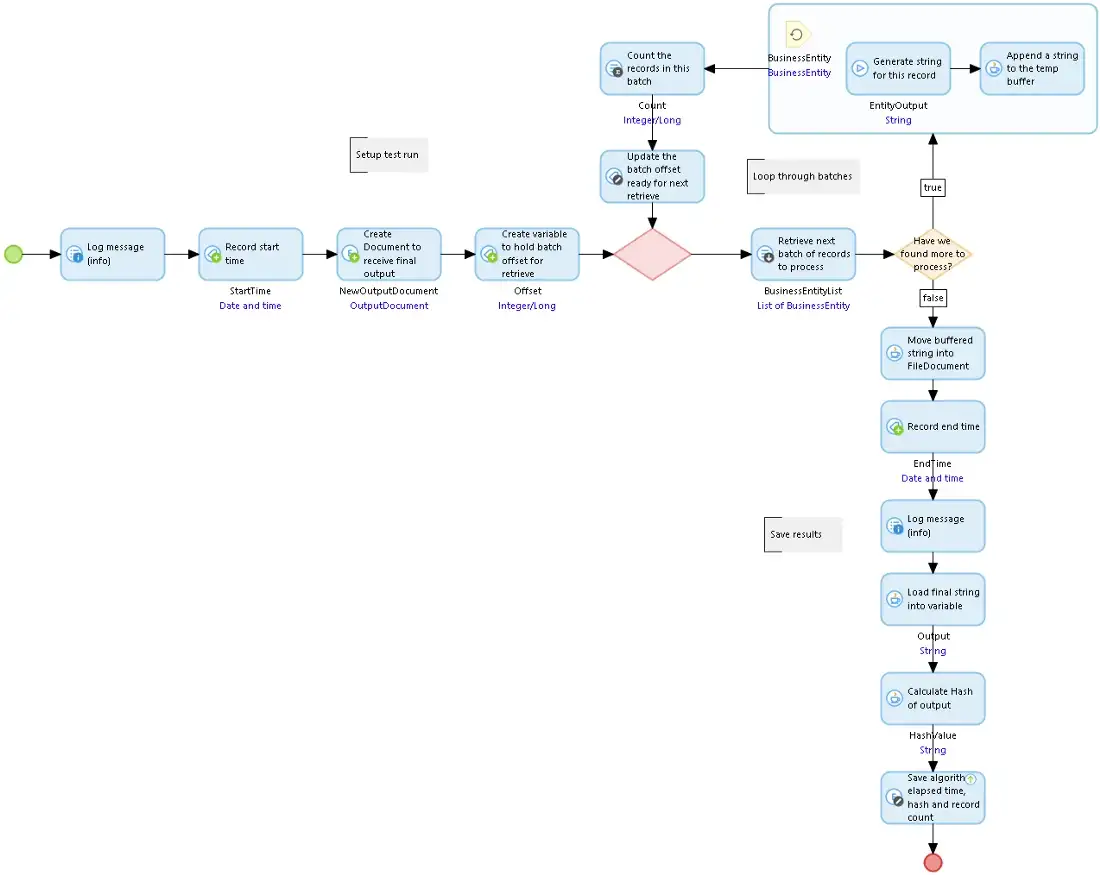
We have a list of Mendix objects and we have a microflow that will generate the text we want from one of those objects. To keep things simple I’ll just work with a single data entity though in a real scenario there could be large trees of objects involved. OutputDocument is the FileDocument specialization that receives the results of the string generation process.
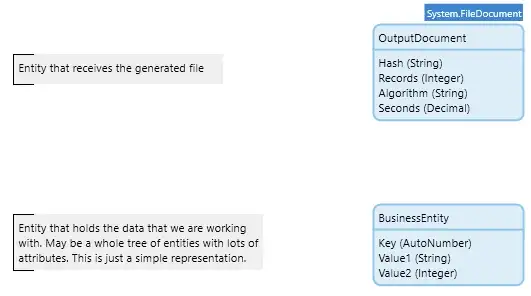
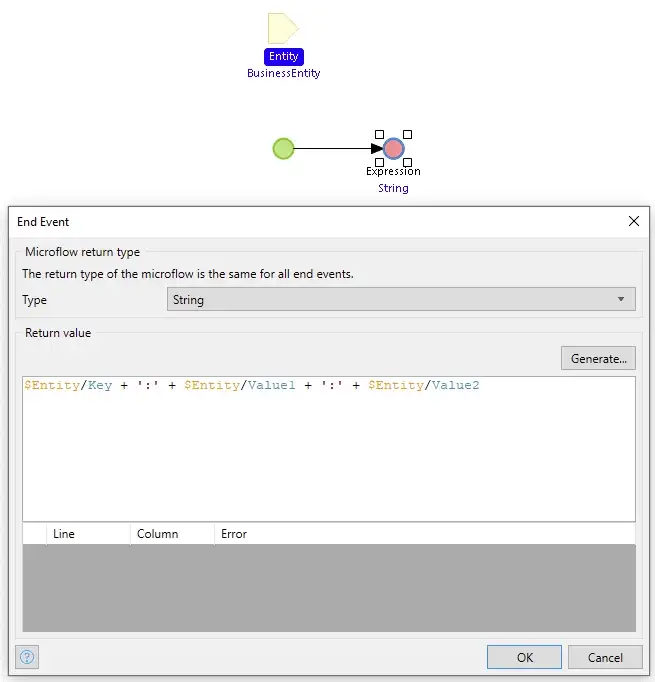 The GetEntityToString microflow that generates the text for an instance of BusinessEntity
The GetEntityToString microflow that generates the text for an instance of BusinessEntityTo produce the output file, we pull the data records out in batches of 2,500 records, pass over the list of objects, and append the text generated for each to a collection string that grows in size. When the list is exhausted the string we have accumulated is written to an OutputDocument. The created OutputDocument also records the algorithm used, the number of records processed, the time it took to run the test, and the hash of the generated file. The hash is generated and saved so that we can confirm that all the methods used to generate identical output are from the same source data.
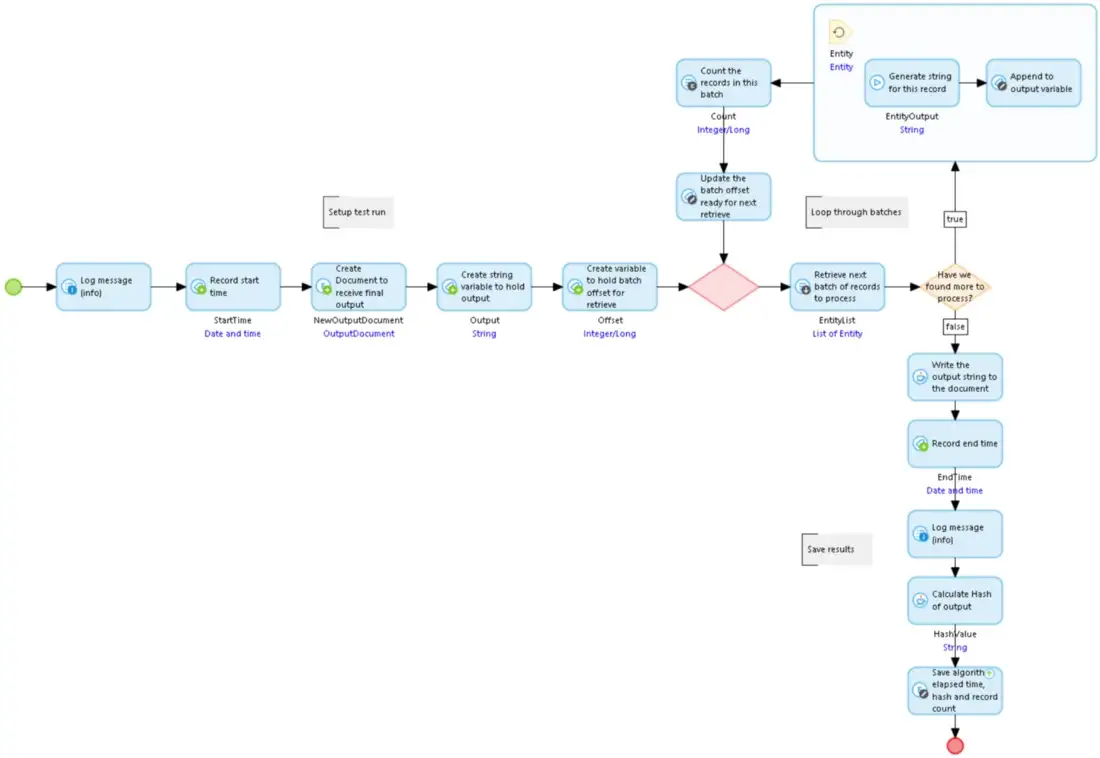
So let’s run this.
I prime the database with 25,000 records with ‘random’ text strings of 500 characters each and random integer values and then run the microflow above.

That gives us an average of 78.81 seconds to build the string and save it into the FileDocument. Now let’s double the data size to 50,000 records and rerun the microflow. I suppose we might expect it to take something under 200 seconds. We should at least assume that now the batched retrieves will be slower as the volume of records has increased although we have an index on the Key.

Oh wow! So that was an average of 334.05 seconds. I won’t try a really large set of data unless I have a film or two to watch while it runs…
So why should a doubling of the volume of the data result in a four-fold increase in elapsed time?
Well, we can’t be completely certain without using profiling tools, but we can make an intelligent guess as to the main culprit.
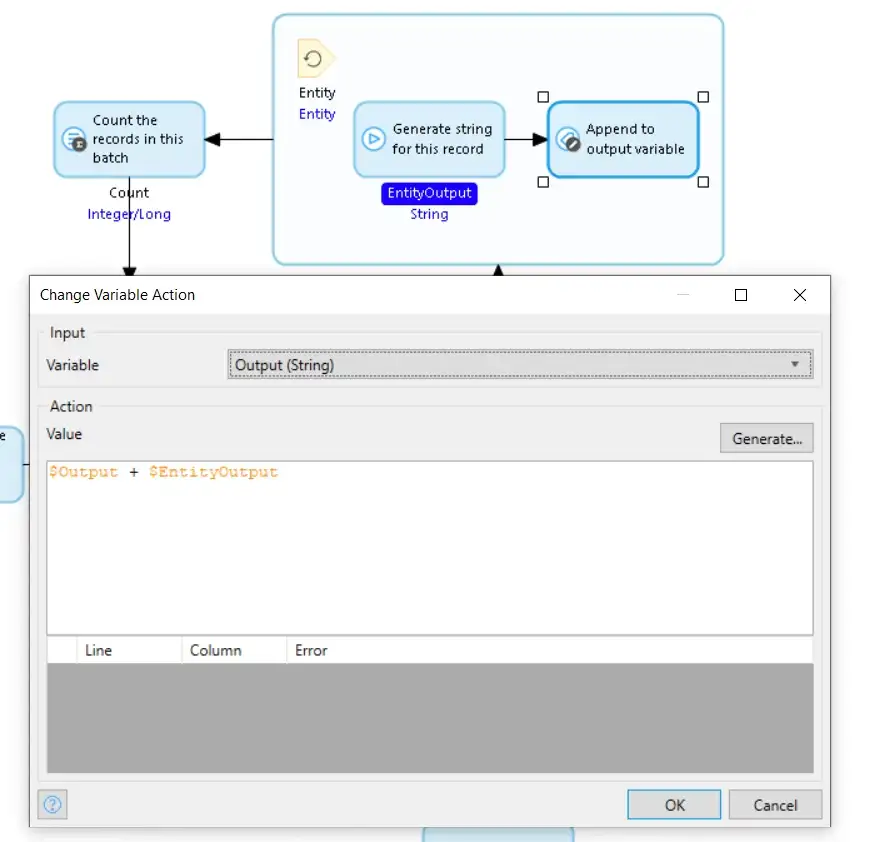
The Change Variable action appends the string that is returned from the GetEntityToString sub-microflow to the previous results already stored in the Output variable. Except it doesn’t do that exactly. In Mendix a string is immutable so in order to create the new value for the Output variable, Mendix has to create a new string consisting of a copy of the original Output appended with a copy of EntityOutput, and save that new string in place of the previous Output value, which is discarded.
As the value in Output gets longer, the amount of text copying increases, and the process becomes more and more time and resource-hungry.
So let’s try a bit of re-engineering using some Java code to see if we can avoid the repetitive copying of long strings and bring down the execution time.
Memory Buffer
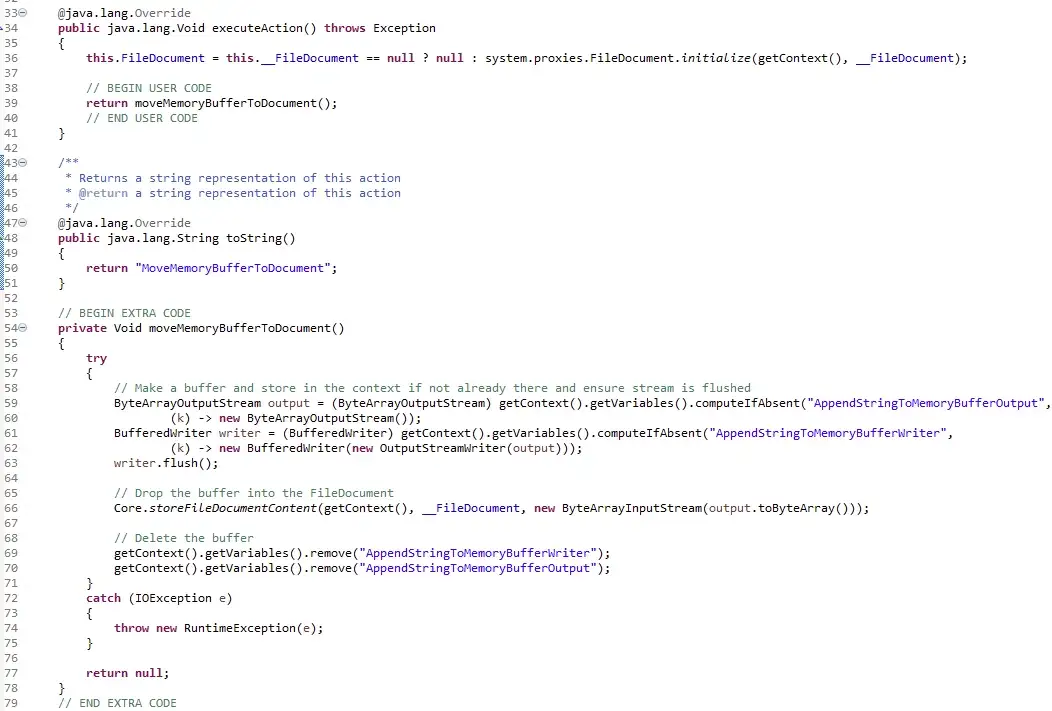
Instead of building the long string in a Mendix variable string, here we shall build the string in a buffer that is stored in the context of the current user action, and then at the end store that buffers into the FileDocument. The context is only accessible from a Java Action, so we have to build this in Java.
The microflow we use is very similar to the original but it calls one Java action to append the next string onto the buffer stored in the context memory, and another Java action to move that completed into the FileDocument at the end.
The two Java actions look something like this. We are using a ByteArrayOutputStream to store the data which we then convert into a ByteArrayInputStream to move the result into the FileDocument.

So when we run this what do we get?
Well for 25,000 records we get an average of 1.90 seconds.

And for 50,000 records we get an average of 2.94 seconds.

I think you’ll agree that is a remarkable improvement over the original algorithm (334 seconds against 3 seconds). This seems to indicate that we are on the right track.
But can we improve this further? Although the speed is enormously improved, we are storing a lot of text in a buffer which is the memory of the app, and could end up putting pressure on the Mendix runtime memory.
File Buffer
Another approach might mitigate the potential memory usage issue and still perform better than the original method. This version of the process writes the generated text into a temporary file so that we do not have to keep it in the Mendix runtime memory.
This option is more complex and requires the use of two microflows and two Java actions. The first microflow calls the first Java action which calls the second microflow which calls the second Java action. The reasons for this will be explained later.
To start the FileBufferBuildString microflow sets things up, then calls the BuildStringInFileBuffer Java action, and finally saves the supplementary results (hash, record count, and time) in the Document.
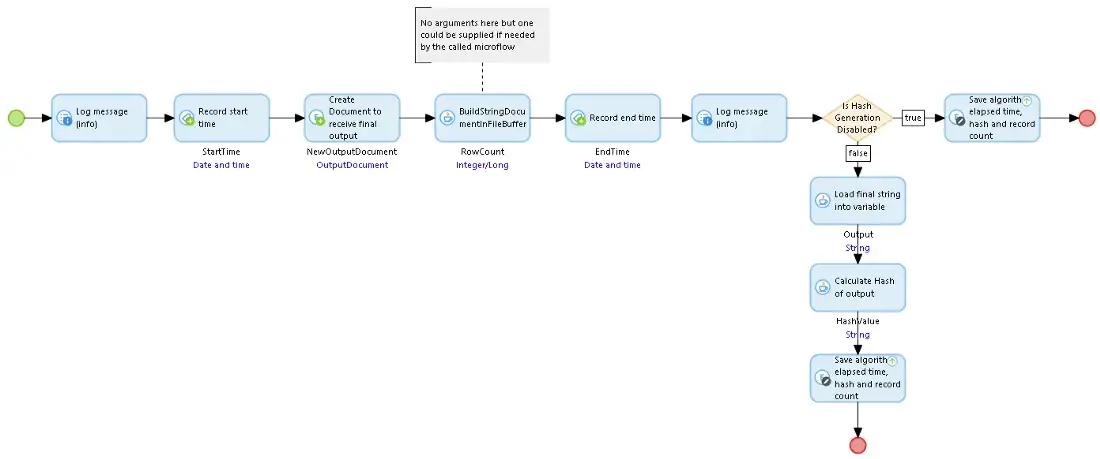
The BuildStringDocumentInFileBuffer Java action takes the FileDocument and a microflow pointer (an optional argument for that microflow), creates the temporary file in the Java temp file location, stores the open file details in the context memory, and then calls the microflow given in the pointer. When that microflow returns it then reads the contents of the temporary file into the FileDocument and cleans up, deleting the file and the context objects.

The SUB_FileBufferBuildString microflow is called by the BuildStringDocumentInFileBuffer Java action. It runs the loop which reads batches of records, generates the strings for each record, and then calls the AppendStringToFileBuffer Java action to get them saved.
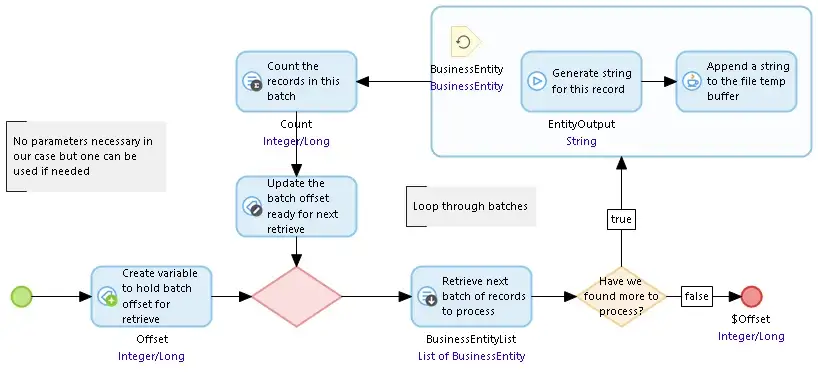
The AppendStringtoFileBuffer Java action pulls the temporary file information from the context (that was saved there by BuildStringDocumentInFileBuffer) and writes the string for a single record onto the end of the temporary file.
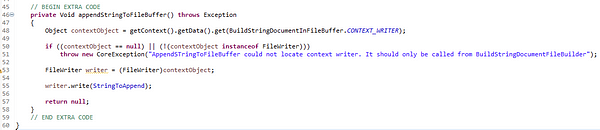
OK, so this arrangement (microflow-calls-java-calls-microflow-calls-java) is a bit convoluted and could be regarded as obscure and going against what I said in my earlier blog post (readability versus maintainability), so it should be well documented for later developers.
There is one good reason for this approach — it is safe. If anything was to go wrong in the process, the first Java action can clean up the temporary file and the open file descriptor before returning back to the first microflow so there is a smaller chance the app as a whole is compromised. There is also an alternative in the app accompanying this blog (called TempStorage) — see How Long Is A String On GitHub — which does not use the nesting of microflows and Java actions but which does require that the caller be much more careful about cleaning up should things go wrong.
So what are the results? For 25,000 records it took 1.23 seconds, and for 50,000 records it took 2.75 seconds.


Memory Buffer and File Buffer are very close in performance but we can see now that the original The Starting Point algorithm performs the least well of the three by a long way, and for the purposes of this exercise we no longer need to use it. Can we choose between the other two?
The Play Off
I mentioned memory usage as being another factor when comparing these solutions so I should get some statistics about that too. To improve clarity let’s use a larger sample of test data — 500,000 records.
The population was set up and then the app was restarted and the Memory Buffer process was run once. With Grafana set up on this Private Cloud, we can get some information about resource usage:
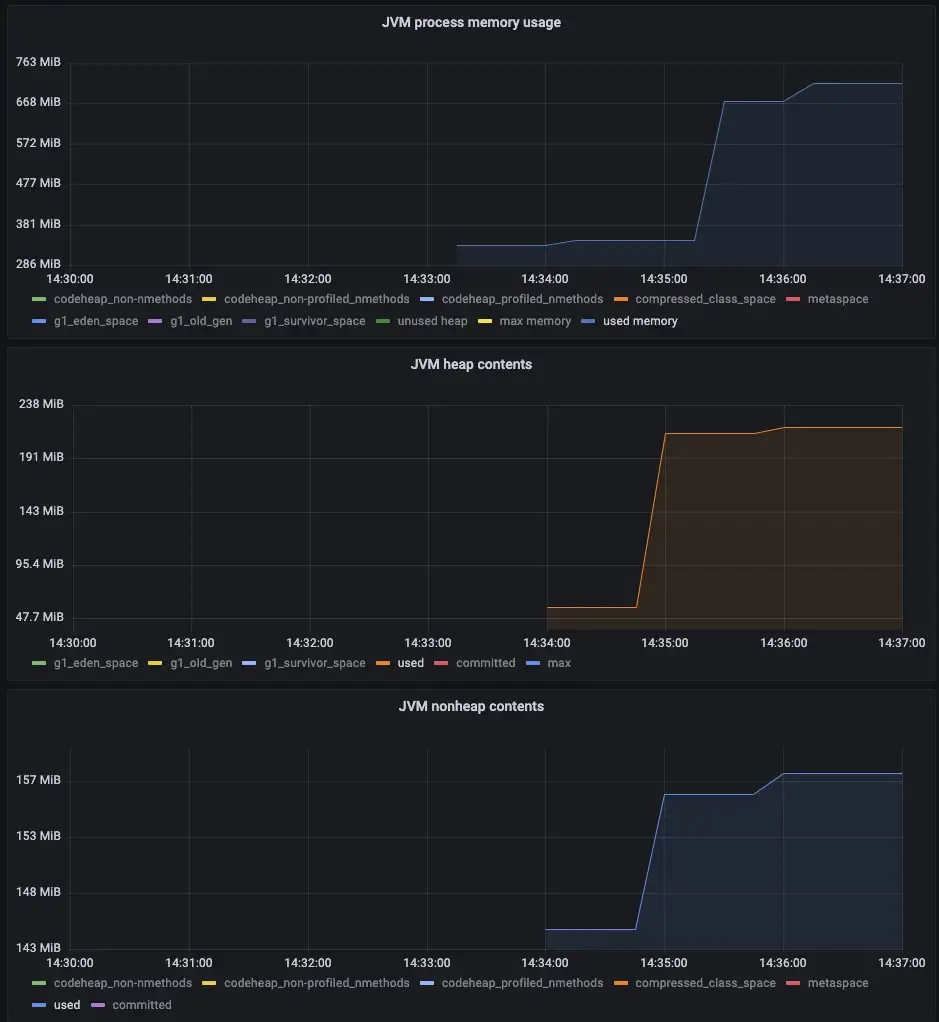
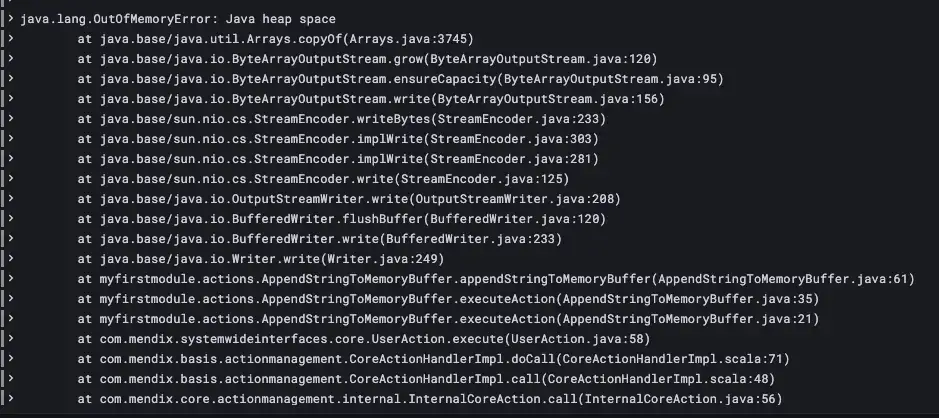
Ouch! Memory Buffer is not strong enough to handle this size of the job and the app ran out of memory while populating the Buffer in AppendStringToMemoryBuffer. Will File Buffer do better? The app was restarted and File Buffer was run:
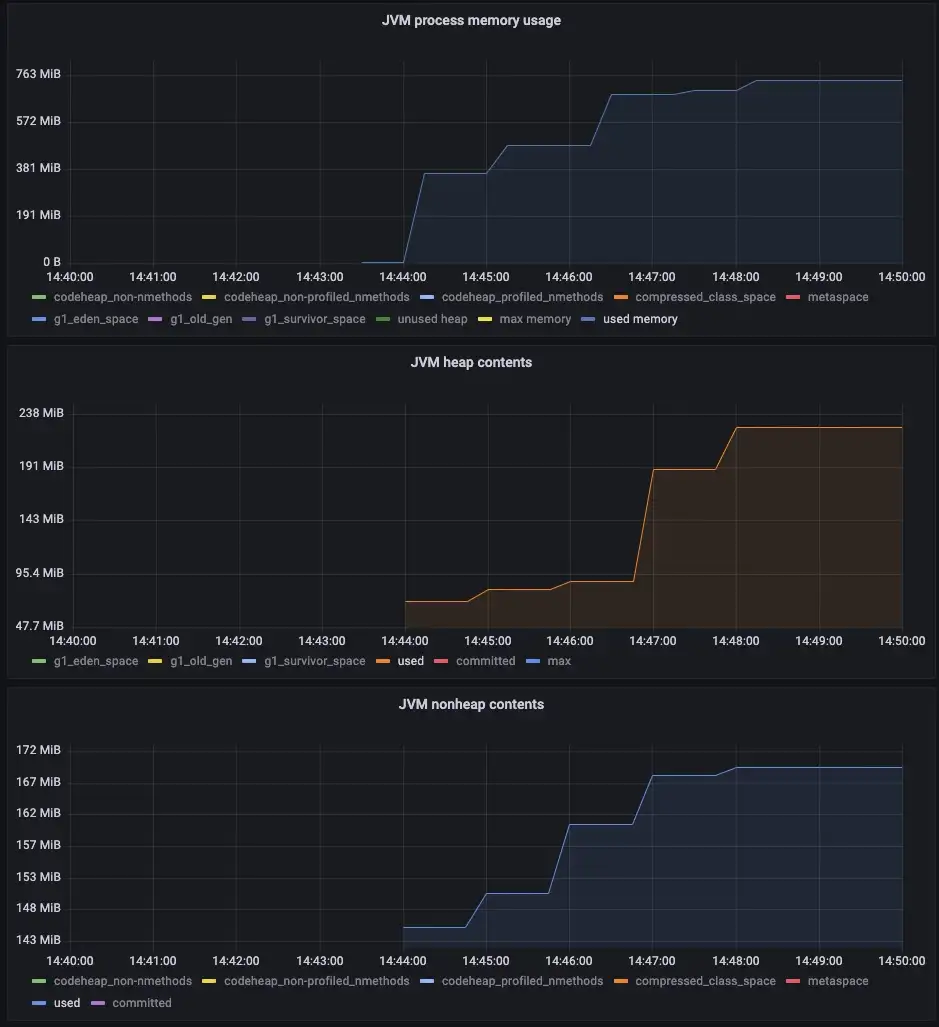
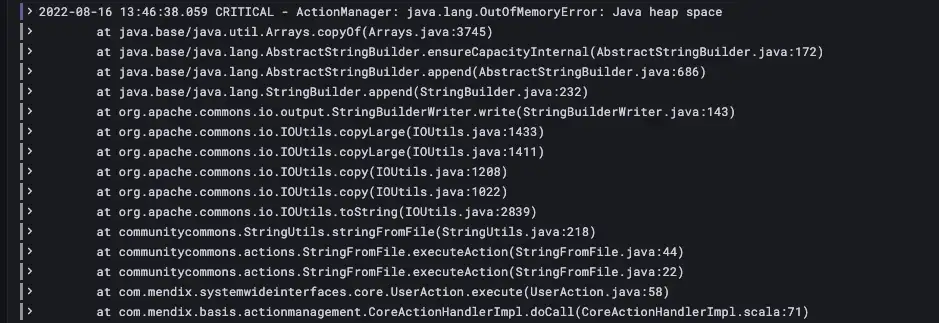
Wait! So File Buffer also failed but this died with Out of Memory after the FileDocument had been successfully created and populated and during the process that reads the entire file that was generated into a String (CommunityCommons StringFromFile) to calculate the Hash value of the data. The file is too big to do that. So I disabled the code that reads the String and calls the Hash action (using a Constant), reran the process and it worked.

So yes, it is completed and we appear to have a winner!
For good measure, I set up a 1,000,000 record set of data and ran File Buffer again and this also completed.

Your Mileage May Vary
How all this performs in a real-world situation of course depends on a lot of factors outside the scope of this article, but I hope this has been useful in showing how, under exceptional circumstances, you can improve the resilience and performance of String generation, and indeed how Java, in general, can be used to help with performance.
In my next Efficiency post, I plan to show how some lengthy operations can be improved by making use of the built-in Mendix Task Queue functionality.
Acknowledgments
My thanks to Arjen Wisse for invaluable advice and Arjen Lammers for the cool CSV module mentioned at the top of this post, from which I unashamedly borrowed ideas.