Unlock GenAI Magic: How to Tailor Foundation Models with Custom Data

Have you ever wondered if and how you would be able to use cutting-edge foundation models with your own custom data without having to manage any infrastructure?
In this post, we explore the exciting possibilities of customizing foundation models to create tailored solutions for your specific domain, organization, and use case, by leveraging the power of Amazon Bedrock and Mendix.
Amazon Bedrock and the chamber of custom data
In a previous blog, we explained how easy it is to create smart and intuitive apps with Amazon Bedrock, a fully managed service that makes available high-performing foundation models (FMs) from leading AI startups and Amazon.
As of March 2024, Amazon Bedrock includes the following foundation models:
- Amazon Titan
- Anthropic Claude
- Cohere Command & Embed
- AI21 Labs Jurassic
- Meta Llama 2
- Mistral AI
- Stability AI Stable Diffusion XL
The list is updated regularly with new and improved models.
Besides the foundation models, AWS enriched Amazon Bedrock with additional concepts as part of the Bedrock ‘toolbox.’. The latest functionality allows the use of custom data with foundation models with the help of knowledge bases and agents.
Of course, Mendix wants to keep our Amazon Bedrock Connector up to date with all the latest functionality and take advantage of the new Amazon Bedrock features. This is why we have released a 2.3.0 version of the connector to include several new operations and examples related to knowledge bases and agents.
The Mendix Amazon Bedrock connector and the order of new operations
In the following sections, we’ll demonstrate different approaches to tailor FMs with custom data.
First off, we’ll discuss Retrieval Augmented Generation (RAG), a technique that fetches data from different data sources and enriches the prompt to provide more relevant and accurate responses by using knowledge bases. We will demonstrate how to use such an Amazon Bedrock knowledge base with the FMs, both with and without using Amazon Bedrock Agents.
Next up is an introduction to prompt engineering. Prompt engineering involves crafting high-quality prompts that guide generative AI models to produce meaningful and coherent responses. You will see how it can be used within your Mendix application.
How to set up and use a knowledge base
A knowledge base is all about data. We will show you how to ingest the new data into a data source, as well as how to use an embeddings model and a destination vector database.
If you want to follow along with the process, make sure that you have access to the following:
- The Amazon console
- Amazon Bedrock (as of March 2024, knowledge bases and agents are available in the regions of us-east-1 and us-west-2)
- Amazon S3
Make sure to also add datafiles to S3. The following formats are supported:
- Plain text (.txt)
- Markdown (.md)
- HyperText Markup Language (.html)
- Microsoft Word document (.doc/.docx)
- Comma-separated values (.csv)
- Microsoft Excel spreadsheet (.xls/.xlsx)
- Portable Document Format (.pdf)
- Log in to your AWS console and navigate to Amazon Bedrock.
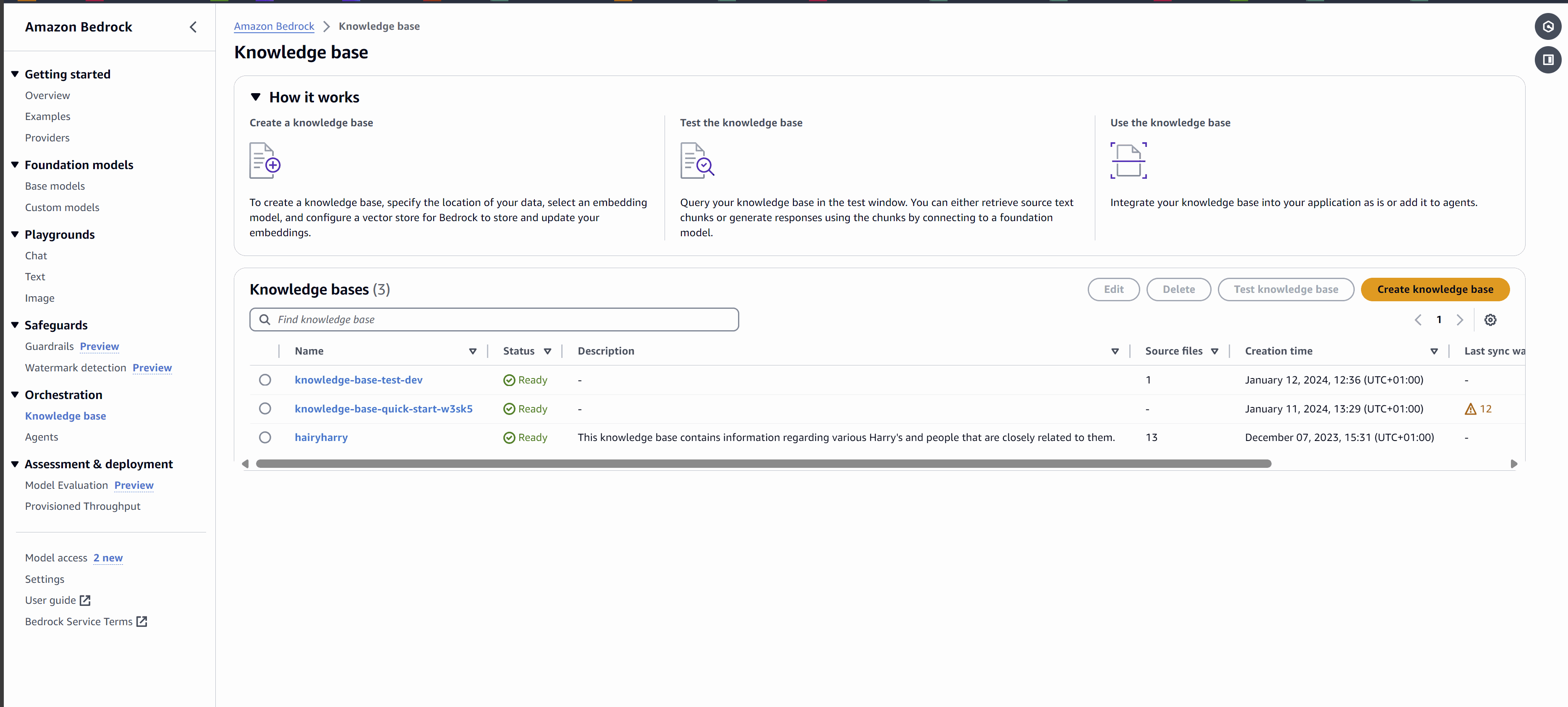
2. In the side menu below the Orchestration section, select Knowledge base, and then click Create knowledge base.

3. Name your knowledge base, as shown in the screenshot above, and then click Next. You can leave the other fields as default.
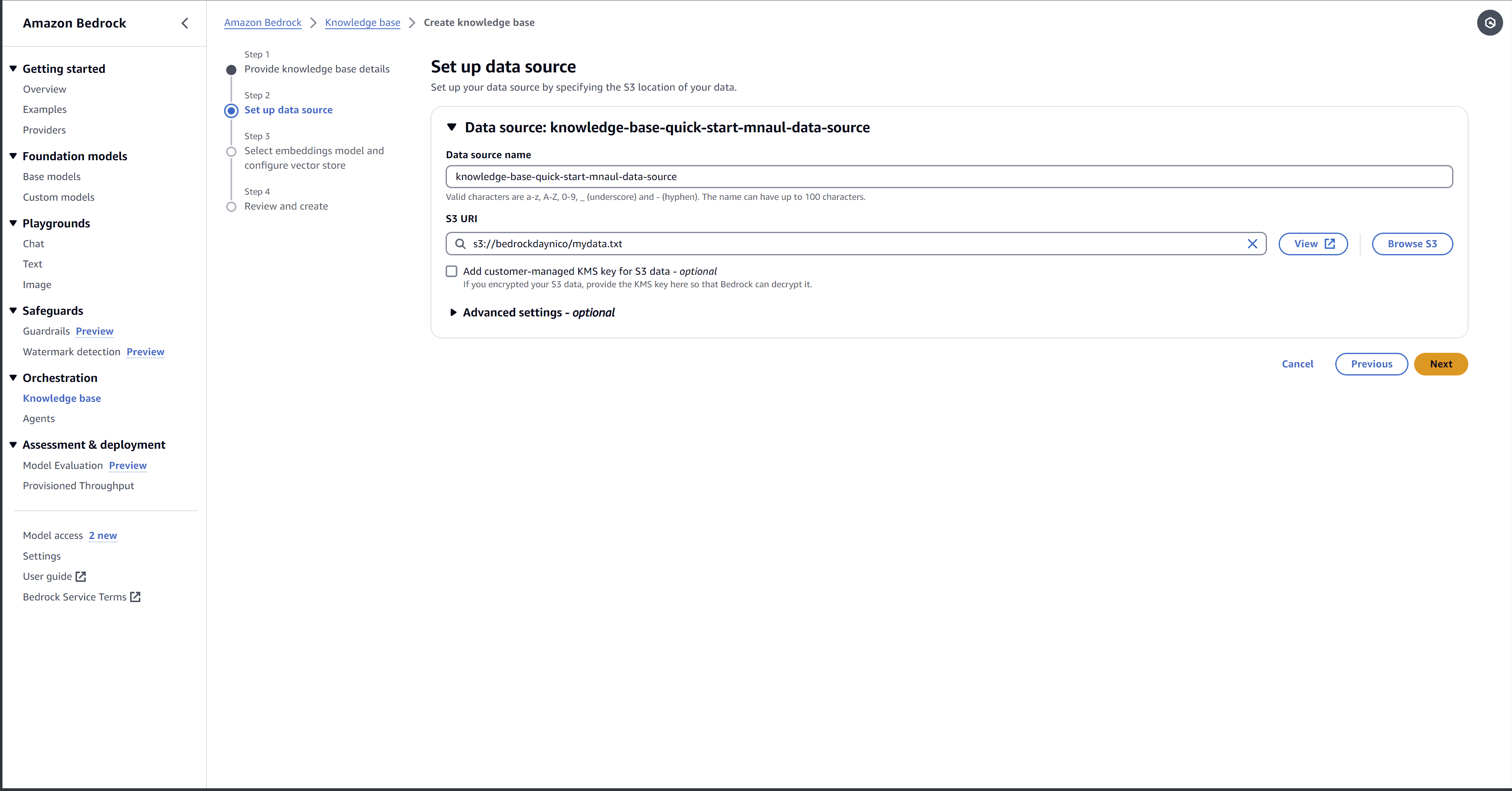
4. Select the S3 bucket and a data file, as shown below.
5. Select the embeddings model that you want to use and then create a new vector database, or use an existing one.
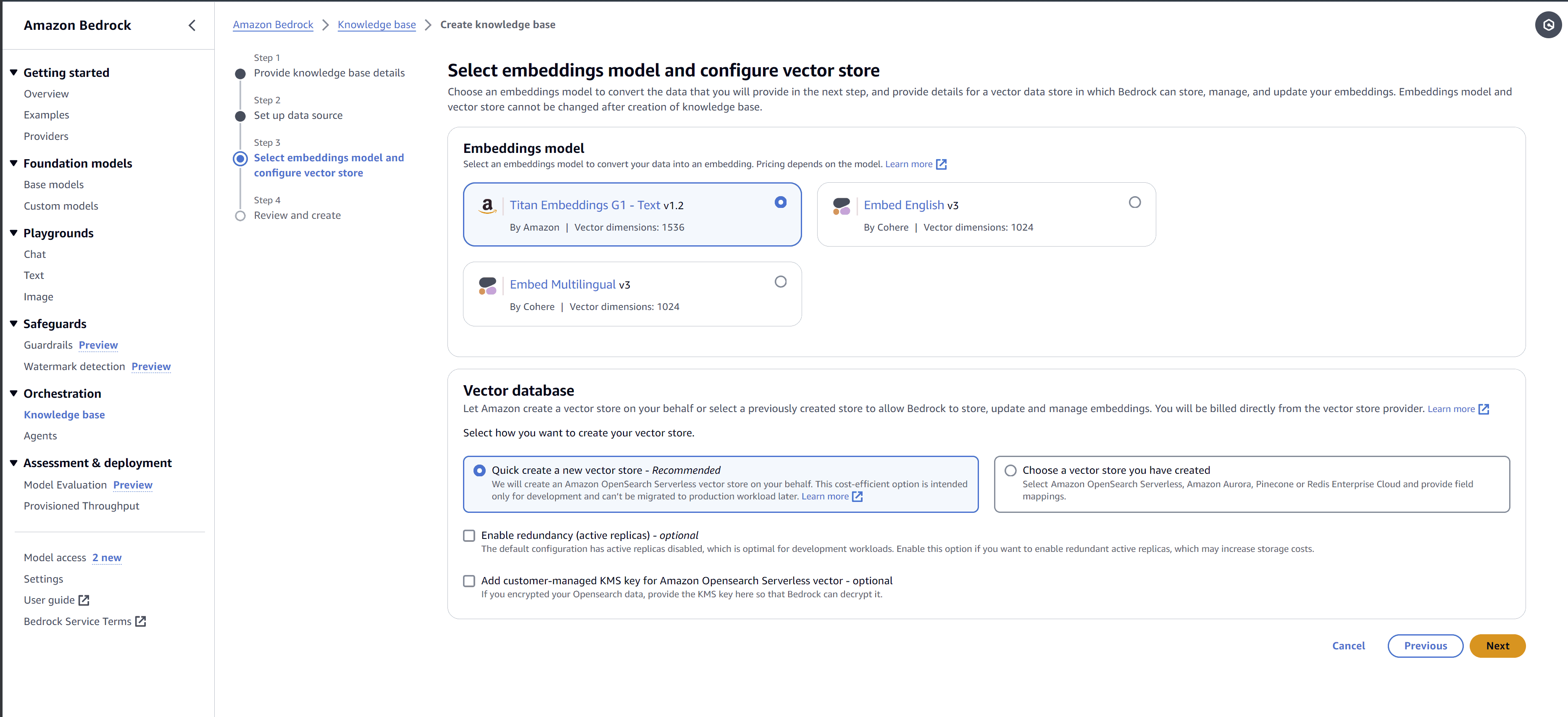
6. Review and create your new database.

To demonstrate how to use the knowledge base with a Mendix app, we will use two examples: one with the Retrieve action, and one with the Retrieve and Generate action. If you want to follow along, you need a Mendix app and the Mendix Amazon Bedrock Connector.
As an alternative, you can also check out the Amazon Bedrock Showcase App, which shows you how to use the Amazon Bedrock Connector to experiment with different foundation models and customize them with your data by using Retrieval Augmented Generation (RAG). The app also shows how you can build agents that execute tasks using your own data sources.
Setting up a Retrieve action
To set up the Retrieve action, you need the following entities.
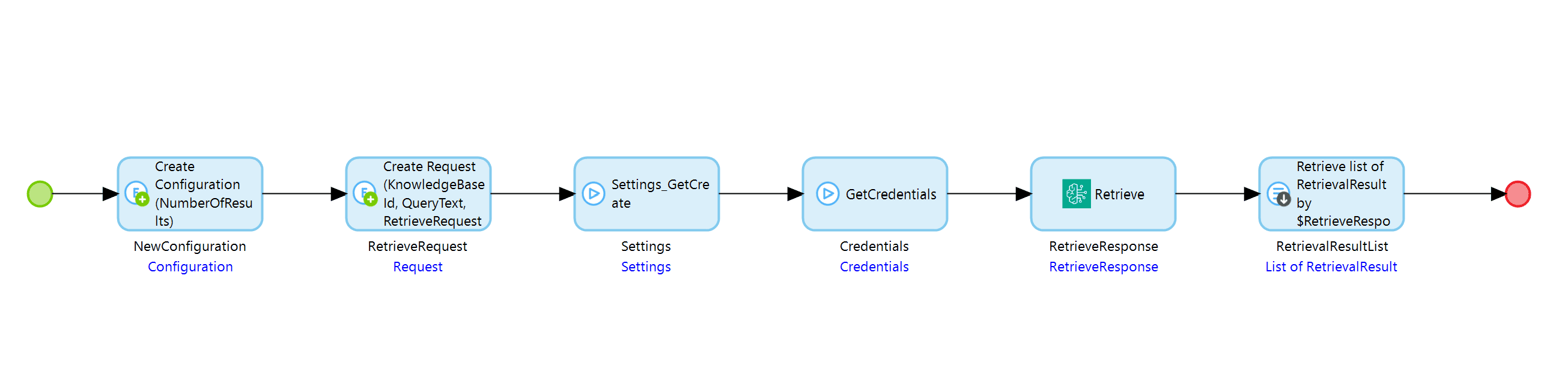
The Retrieve request needs a knowledge base ID, a query text, and an association to the configuration object.
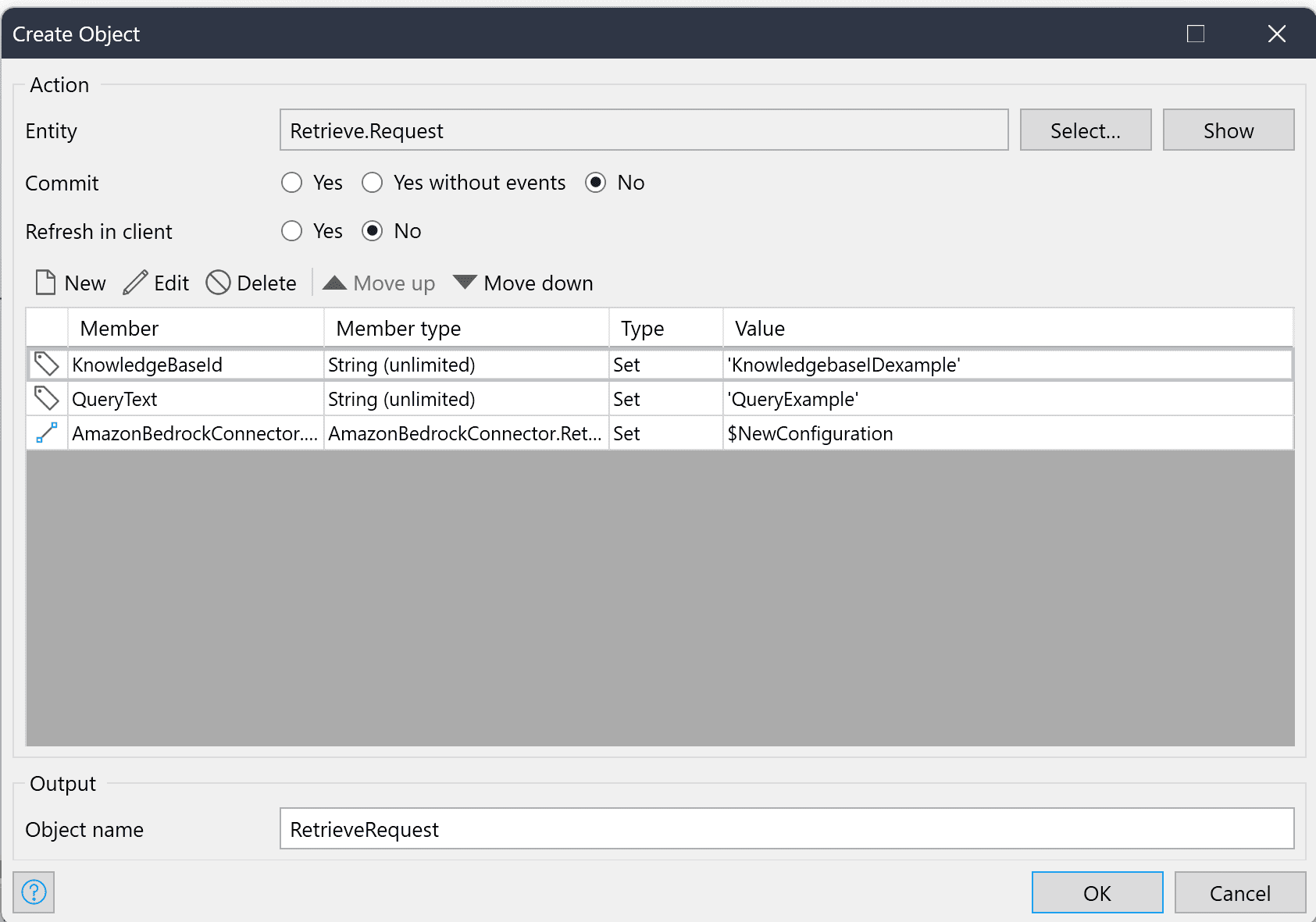
The Configuration object should only contain the number of results.
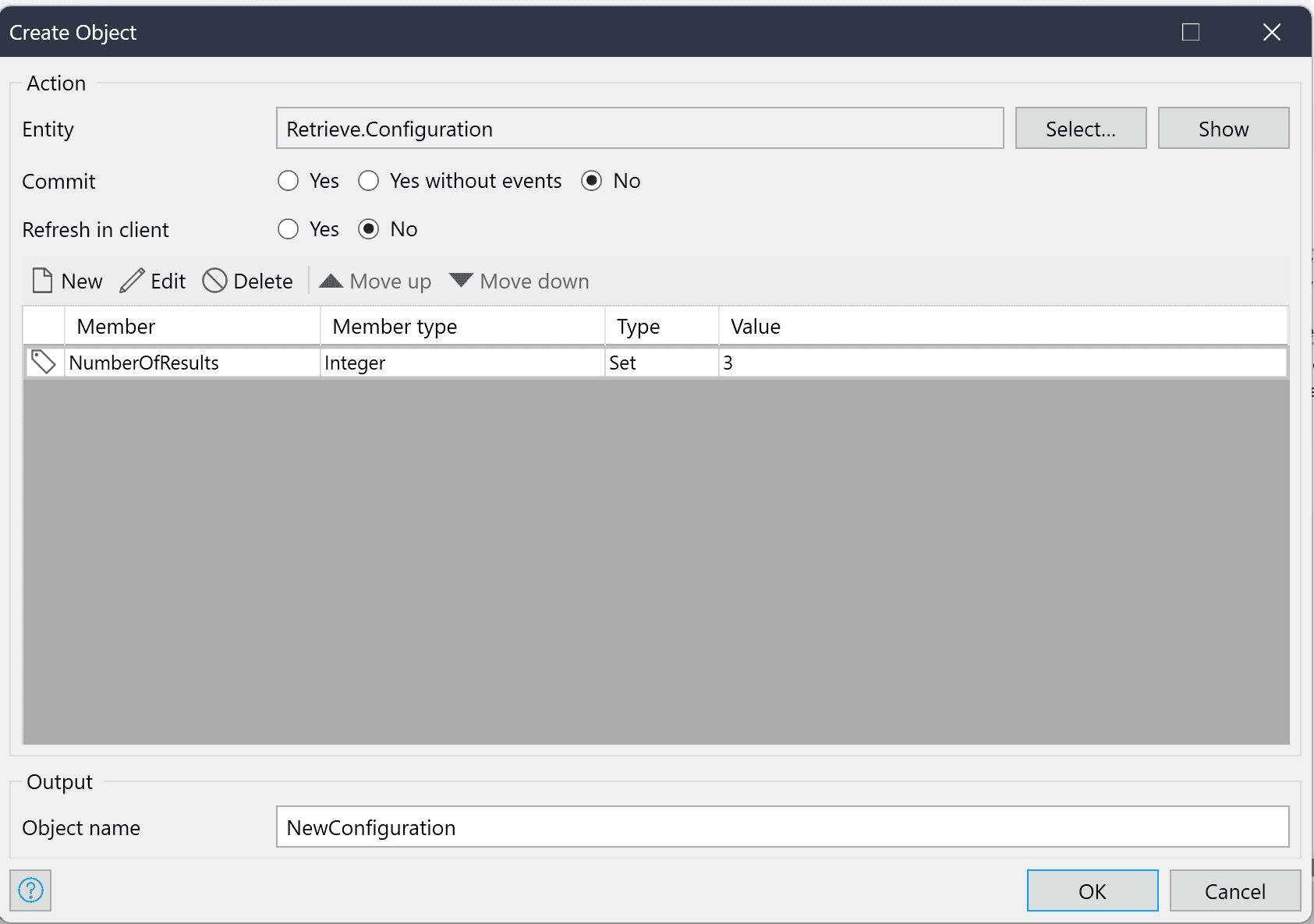
The operation will return an object of the type RetrieveResponse, which contains a list of RetrievalResult objects containing the retrieved text chunks from the knowledge base. The list will have a maximum of NumberOfResults entries where NumberOfResults is the number you specified in the Configuration object.
Testing out the Retrieve and Generate operation
Using the Amazon Bedrock Connector, you can also test your previously set up knowledge base with the Retrieve and Generate operation by setting up a similar microflow to the one seen below:
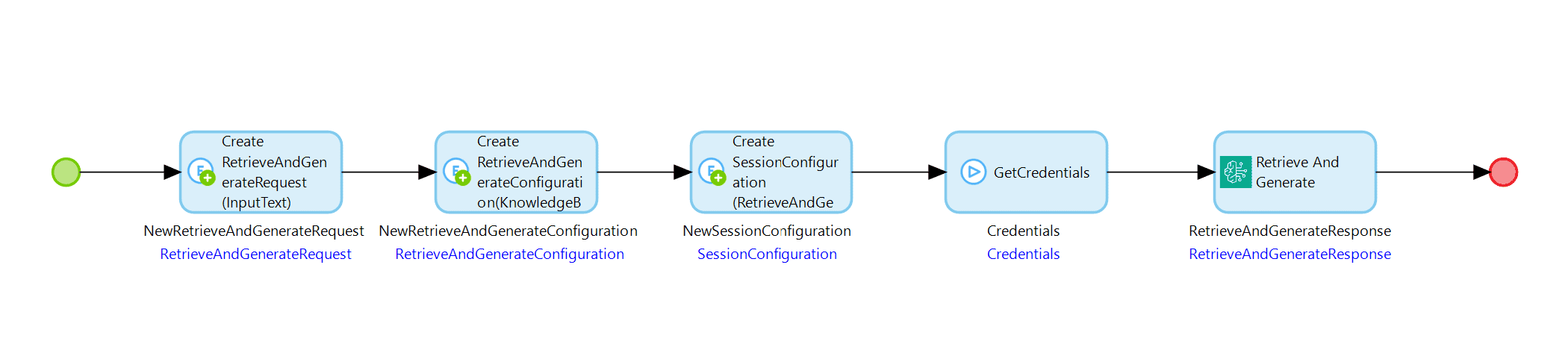
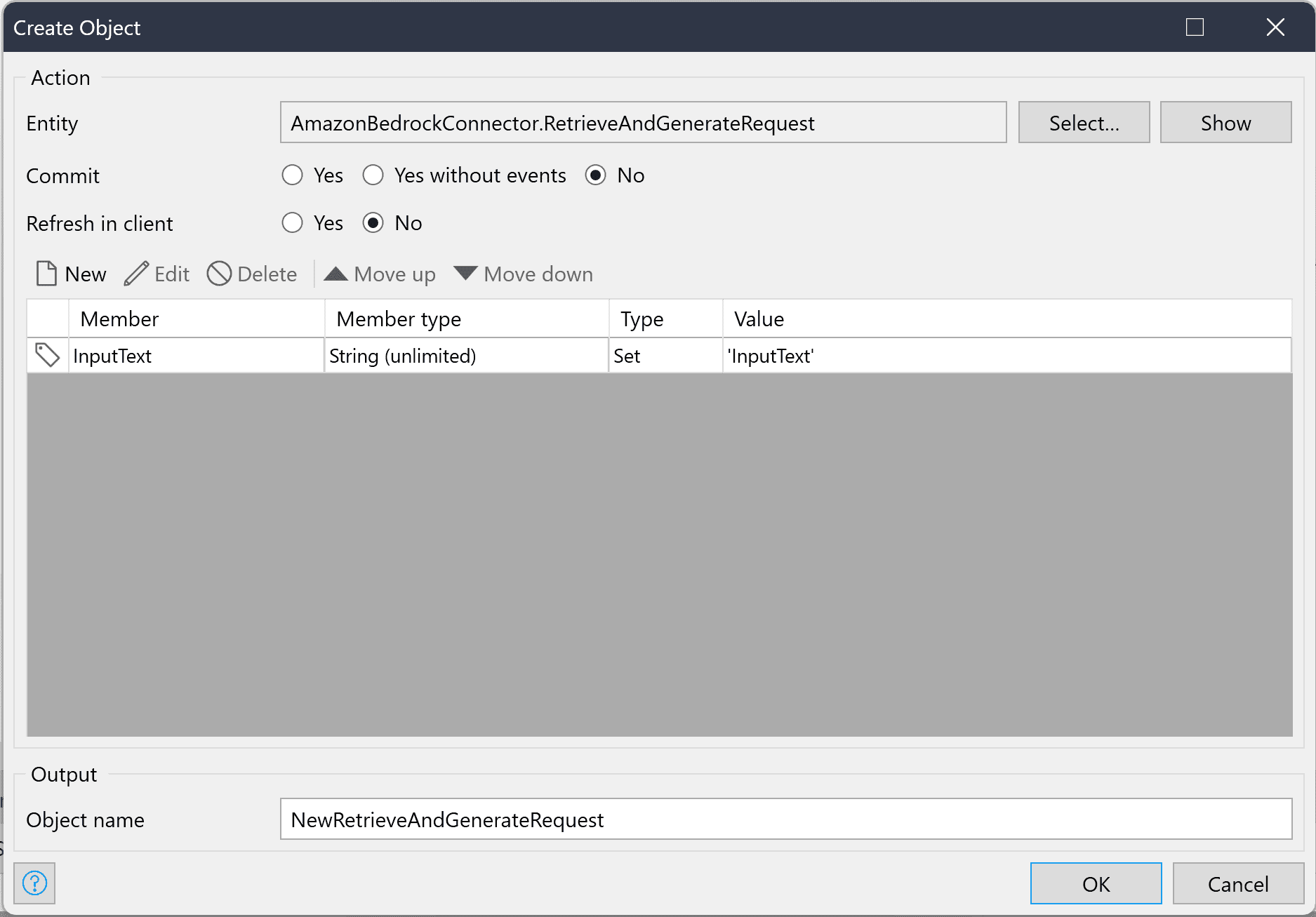
The RetrieveAndGenerateRequest object and the RetrieveAndGenerateConfiguration object are required. The SessionConfiguration object is an optional object that you can add to the request if you need to add a KmsKeyArn to describe the key encrypting the session. Now, let’s go into details for the required objects.
The RetrieveAndGenerateRequest object must contain the input text that you want to query and optionally a session ID if you would like to continue an ongoing session. The RetrieveAndGenerateConfiguration object must contain your knowledge base ID, the ModelARN of the model that you would like to use, and a parameter called RetrieveAndGenerateType, which can currently only have the enumeration value “KNOWLEDGE_BASE” that is set during the object’s creation. The association between these objects must also be set in the RetrieveAndGenerateConfiguration object.
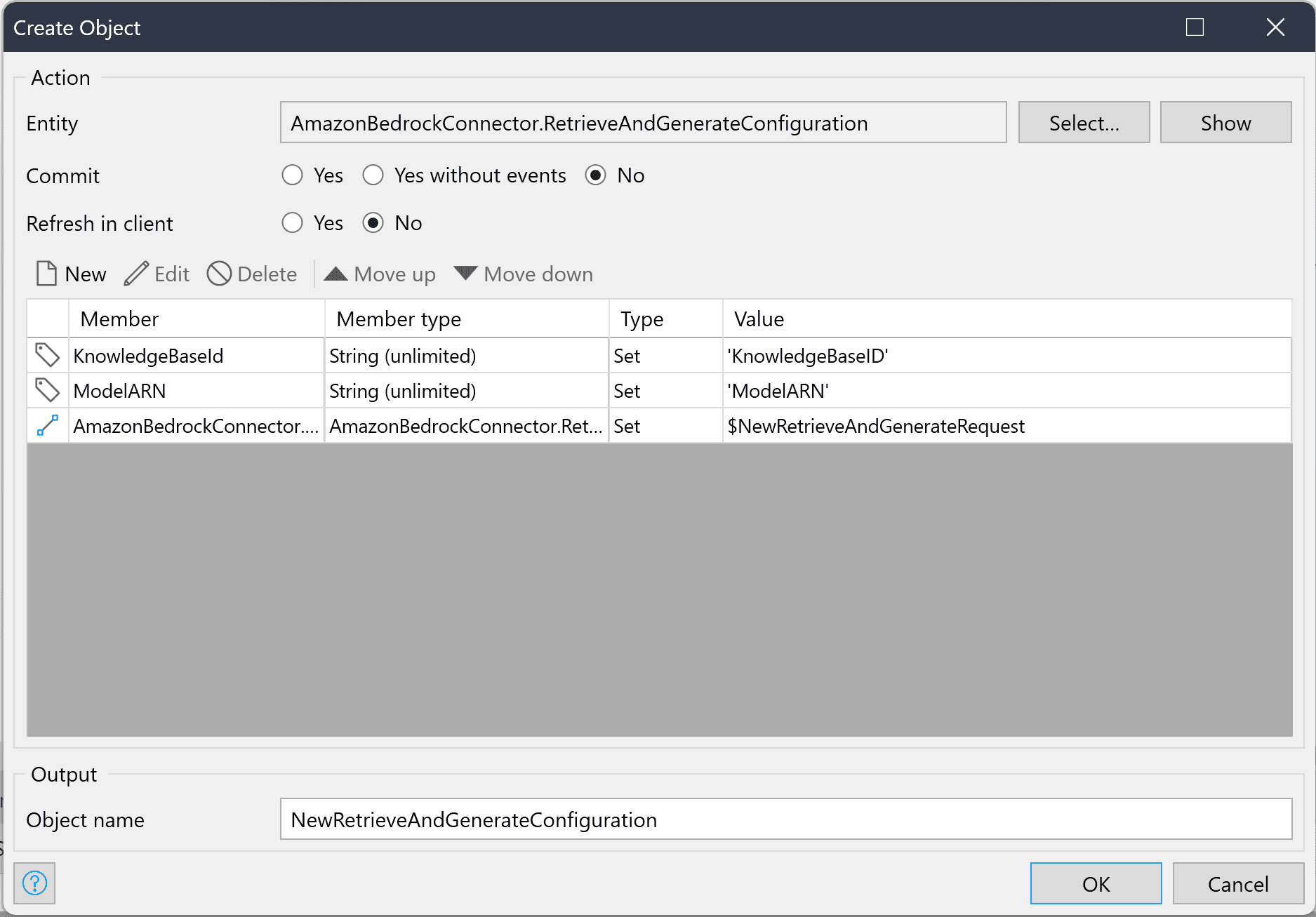
The RetrieveAndGenerateResponse object will give back an output text generated to answer your query using the information inside your knowledge base. The response object will also have a list of Citation objects associated with it, from which you can find information about the retrieved references and the parts used during the output generation.
Let’s take it a step further
To make even better use of the “Retrieve and Generate” and “Invoke Model” operations, structure your queries in more detail to get better responses to your questions. Prompt engineering is the art of writing prompts that result in better responses. With prompt engineering, you can restrict, focus, and adjust the responses you can expect. For example, you can add extra data to the user prompt to be used by the model. This will allow you to make better queries in the knowledge base and your LLM to generate a response in the style that will benefit your use case.
Retrieve and Generate vs Amazon Bedrock Agents
You might wonder whether to use “Retrieve and Generate” or “Invoke Agent” in your application. To provide you with a comprehensive overview of both these operations, let’s look into what is going on in these two operations.
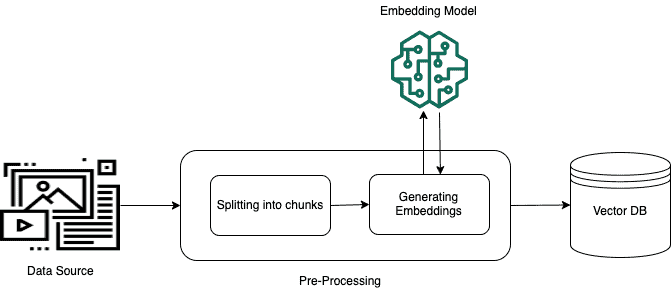
When you add your documents to a knowledge base and sync them, your documents are first split into chunks (if you have configured a chunking method, of course). Then these chunks are converted by using an embeddings model, and written to a vector store. During this process, the given vector indexes are mapped to each chunk, so that the model can locate the most relevant chunks when required.
Although these vector representations are a string of numbers (embeddings) that perhaps have no meaning to us, they contain a lot of meaning to the embeddings model. So don’t think they are just gibberish. The vector database that these embeddings are saved in is a crucial component in the use of all operations with knowledge bases. You can take a look at the image below to see an illustration of the pre-processing of data for the vector database we found in the official Amazon Bedrock documentation.
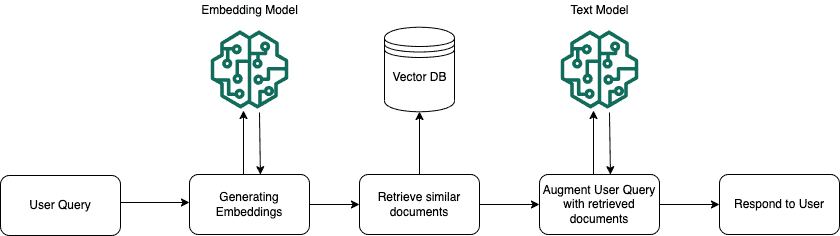
The illustration below illustrates the Retrieve and the Retrieve and Generate operations. When a user query is made using the Retrieve or Retrieve and Generate operations, that query is converted to a vector by using the same embedding model as for the knowledge base creation.
Then, the vector representation that has been assigned to the user query is compared with the vectors in the vector database to find the chunks that have semantic similarity. Afterwards, the chunks found to have similarity are located and given back to the user. This part is the process that happens until the red line that can be seen in the image below and describes the Retrieve operation.
Afterwards, the converted texts are given to a Text model with the user query to generate a response for the user. The whole of this explains the Retrieve and Generate operation.
Not all foundation models might be a feature of the Retrieve and Generate operation in Amazon Bedrock when you would like to use the operation. However, I’m sure at one point in time most of us have had to find a workaround to a problem when plan A didn’t work out as well as we thought. So, as fellow developers, we have also come up with a workaround to be able to use a similar feature with any foundation model available in Amazon Bedrock.
As explained above, the Retrieve and Generate operation retrieves relevant information from your knowledge base. This information is then given to a Text model with the user query to generate a response. This feature can be replicated and completed in two separate steps.
First, use the Retrieve operation to receive related information from your knowledge base. Then use the Invoke Model operation with a follow-up query that includes the received relevant information as well as your initial question. Using this method does mean that you will need to create the JSON request body for the Invoke Model operation yourself. However, you will be free to use any foundation model that Amazon Bedrock provides.
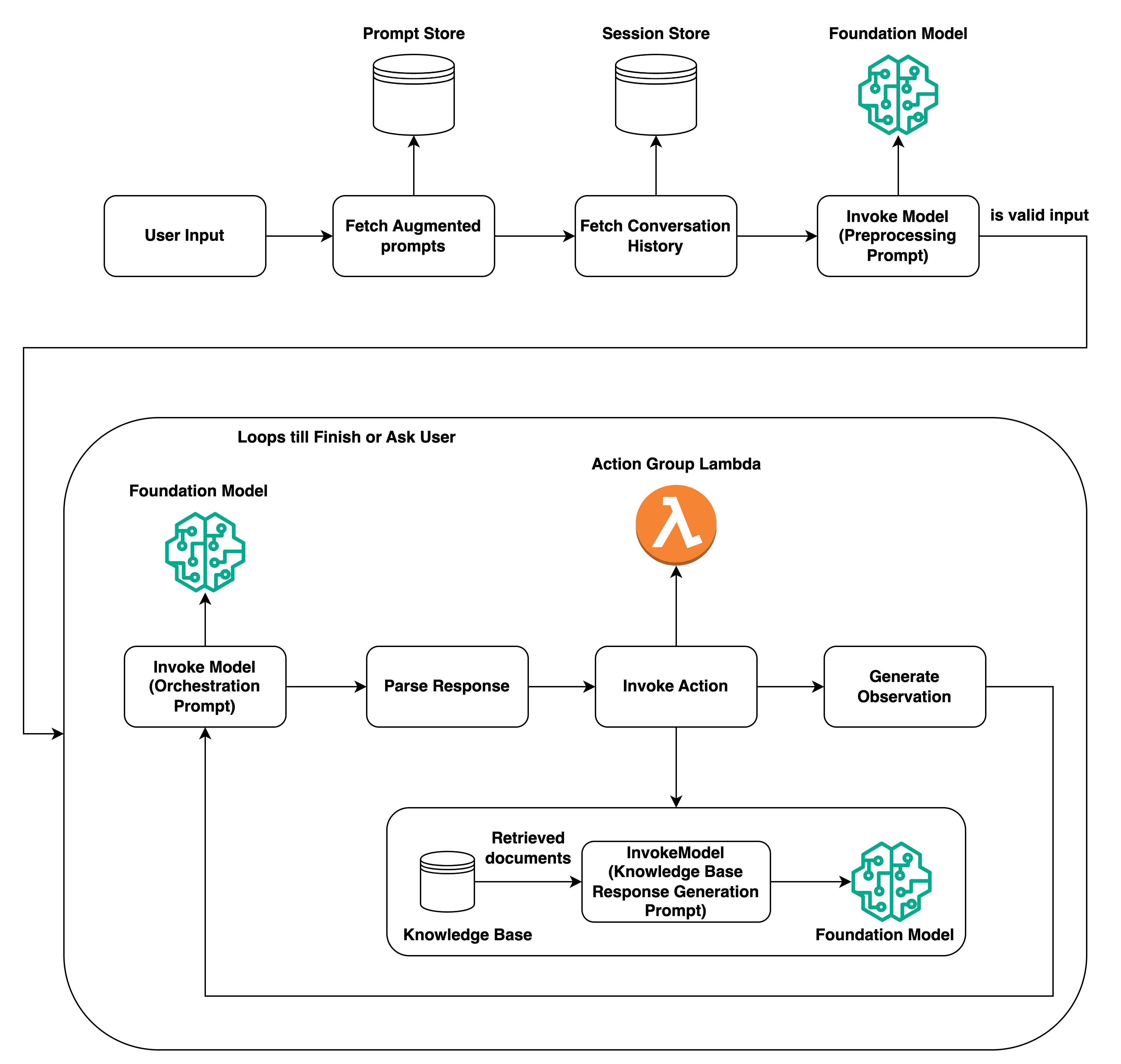
Let’s now see how invoking an agent differs by looking at the elaborate illustration below from the Amazon Bedrock Agents documentation.
The operation starts with a user input. Before anything else the augmented prompts that will be used during the pre-processing, orchestration, knowledge base response generation, and post-processing steps are fetched from the prompt store.
If you have used the invoke agent operation before, you might be thinking “Prompt store? I have not created any prompts, but the operation is somehow working…?”.\ Well, you would be right in this case because Amazon Bedrock has default prompts that are used for these steps configured from the start. However, these prompts are completely configurable to be in line with the needs of your application, which is one of the features that displays the flexibility of Agents in Amazon Bedrock. Then, if you would like to keep the history of the conversation in mind for the query, the history is fetched according to the session before the preprocessing prompt—filled out with the retrieved information and your query—is made to the foundation model. If the query is accepted as a valid input, the loop shown in the illustration begins.
The operation will proceed into the loop and use the previous information to fill out the configured orchestration prompt and invoke the foundation model. According to the parsed response, the Invoke Action section of the illustration is set in motion. What this action will be, is completely up to the arrangement of the user.
Unlike Retrieve and Generate, agents can perform different operations using multiple knowledge bases, and even orchestrate tasks using Lambda functions. The possibilities are endless and not limited to just receiving the output back. The operation can be set up to continue looping until an intended result is found or an intended action occurs by using the capabilities of Amazon Bedrock agents. What exactly these actions may be… Well, I think we’ll leave that for a future blog!
Exploring AI Customization with Amazon Bedrock and Mendix
In this post, we’ve delved into the exciting realm of tailoring foundation models with custom data using Amazon Bedrock and Mendix. With the new functionality introduced by AWS, it’s now easier than ever to incorporate custom data into foundational models, enriching prompts and generating more relevant responses. Through step-by-step guides, we showed how to set up a knowledge base, ingest data, and utilize Mendix applications with the Amazon Bedrock connector to harness the power of these techniques.
Additionally, we compared Retrieve and Generate and Invoke Agent operations, shedding light on their differences and capabilities. While Retrieve and Generate offers a streamlined approach for retrieving information and generating responses, Invoke Agent provides greater flexibility, allowing for orchestration of tasks using multiple knowledge bases, lambda functions, and more.
Check out the Amazon Bedrock Showcase App, to get an overview of all the operations currently possible with the Amazon Bedrock Connector. With Amazon Bedrock and Mendix, the possibilities are endless. We’re just scratching the surface of what can be achieved in the realm of AI customization and integration.
This blogpost was co-written by Agapi Karafoulidou and Ayça Öner.