Recently I ran into an issue where the data I was importing into my application was not getting updated though I thought for sure I had my process built exactly as expected.
Let me start with a little background on the issue. As I said, I was importing records into my application, let’s say around 10,000 records that I then wanted to update and mark as “processed”.
So I built my import using web services and my data came in no problem. I then built a process that used a limit of 1,000 records at a time and updated them. A retrieve using a limit allows you to process a subset of the data within your table that ensures you are not placing too many records into memory and potentially impacting the performance of your application.
Additionally I was using an offset; an offset allows you to say where in your table you want to start the retrieve. Once you have this put in place you can iterate your process increasing your limit to be sure you process all of your records. As shown below:
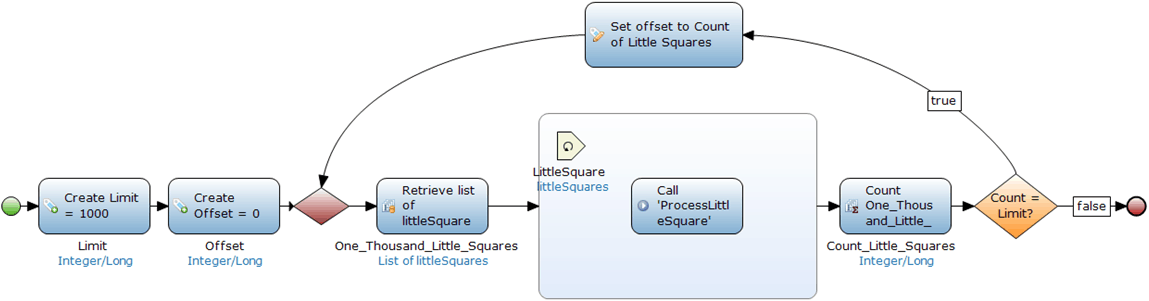

So, a basic explanation of the picture above:
- Create an integer equal to the number of records you would like to “limit” your retrieve to (in this case 1,000)
- Create an integer equal to your offset. For this example, I need to start at 0 which is the first record of course.
- Retrieve a list of your entity using a custom retrieve.
- Define your limit as $Limit
- Define your offset as $Offset

- Iterate over your list and perform whichever process you want
- Count the number of entities your retrieved in the retrieve action
- Check to see if the number entities retrieved equals the limit you defined
- If yes (true), then go do it again there may be more
- If no (false), then you must have reached the end of your list
Pretty easy right? Well unfortunately I missed the most important thing, incorporating a sort within my retrieve.
Let me explain why this is important. Below you’ll see the result of a retrieve of “little squares” as defined in my microflow above:

Let’s just say the picture above is a table with 100 little squares. I’m retrieving a limit of 10, with an offset of 0. The highlighted squares are what get retrieved and processed. Once this process finishes, we make another retrieve on the database after changing the offset to the number of the previous retrieve (10).
Now my record set is retrieved but since I didn’t define a sort order the retrieve arbitrarily returns the list in no specific order. Since my offset is 10 I start with record 10, unfortunately it could be records that have already been processed. The image below shows the second retrieved list and the highlight records are the ones that we will then process:

Now the image below shows you the retrieve with a sort applied. In applying the sort we want to be sure that we use the most unique attribute possible. This will help us to be sure that the retrieved list is always the same and we are sure to process each and every record in the table.

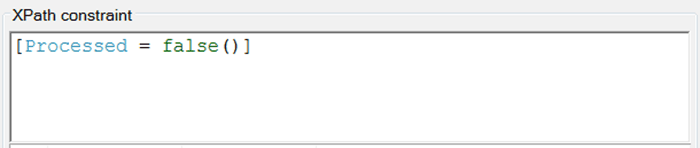
Now sometimes it’s not wise to implement an offset. Let’s picture this example; the little squares are either white (not processed) or blue (processed). I want to retrieve all of the records that are not processed and process them. In my retrieve action I apply an XPath constraint of [Processed = false()].
Again, I have a table that has 100 records all of which have not been processed as you see pictured below. I use my limit of 10 and offset of 0 allowing for me to get the first ten records. I will then process each of those records:

I’ve processed the ten records and now my data set looks like the image below. If I apply my modified offset but continue to use my XPath constraint, my process will skip the first 10 records of the resulting data set causing only a partial update.

From my experience the examples provided in this post are the most common examples of limit and offset retrieval and processing. There are other situations where data may or may not be processed based on attribute values or other reasons. Always be sure to use a sort that will cause the list to be as static as you possibly can:

So in summary, when dealing with retrieval of large data sets you should:
- Use limits and offsets
- Limits should be set to no more than say 3,000 to minimize impact on cache memory and system performance
- Offset should be used if your retrieval constraint doesn’t cause the record set to change. It should also be a variable and be set to the place in your list where you want to start your processing.
- Use sorting on the most unique attribute to make your retrieve static over your iterative process
As with any process you create in Mendix, always be careful to consider how the choices and actions you make within it impact your data. I hope the preceding post sheds some light on this subject and happy modeling to you all!