
Can you complete coding challenges using low-code? Sure! But why?
When applying for software engineering jobs the current trend for preparation is to complete “LeetCode” challenges. LeetCode is a site made up of problems specifically designed to prepare software engineers for potential interview questions. There are currently more than two thousand challenges available, all designed to test a candidate’s knowledge of efficiency, patterns, and problem-solving.
So here we have a whole site full of coding challenges specifically designed to test coding skills in multiple languages. Having done my time in C# and JavaScript I could easily try and tackle these problems using one of those languages, however, that’s not what I do anymore. I’m a low-code evangelist now. Surely, I should try and tackle these problems in low-code?
Granted low-code is not designed for these kinds of problems, specifically. It’s a platform intended for building business applications, not for problem-solving that focuses on being super-efficient. However, there’s a reason these challenges are used to test candidates: They can be applied to real-world applications. So, let’s have a go at this challenge and see if we can complete it. Then we’ll talk about how this could apply to a real-world application and how Mendix could be used to build it.
Challenge one: Two Sum
This challenge involves taking an array of numbers and finding the index of the two numbers that, when added together, make the target value. On its face, the challenge is simple: Take the array and loop through it, then for each value, loop through again and find the value you need to make the target. Inefficient, but simple. So that’s where we’ll start.
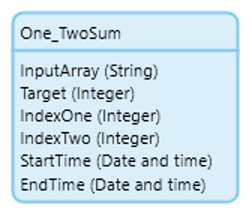
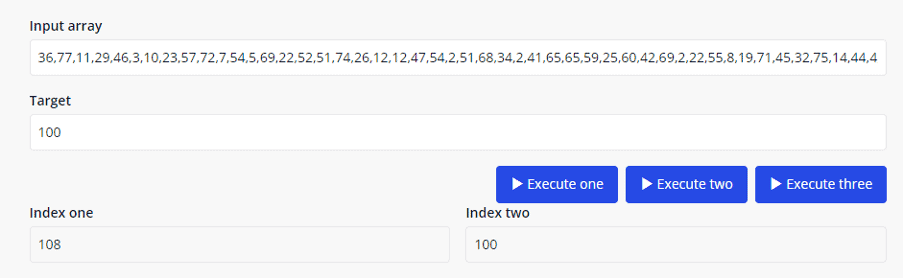
First, we create a simple entity that takes in a string to represent the array, an integer attribute representing a target value, and a couple more values needed to store the indexes of the items that satisfy the conditions (shown below). We’ll also add a start/end time to track efficiency.
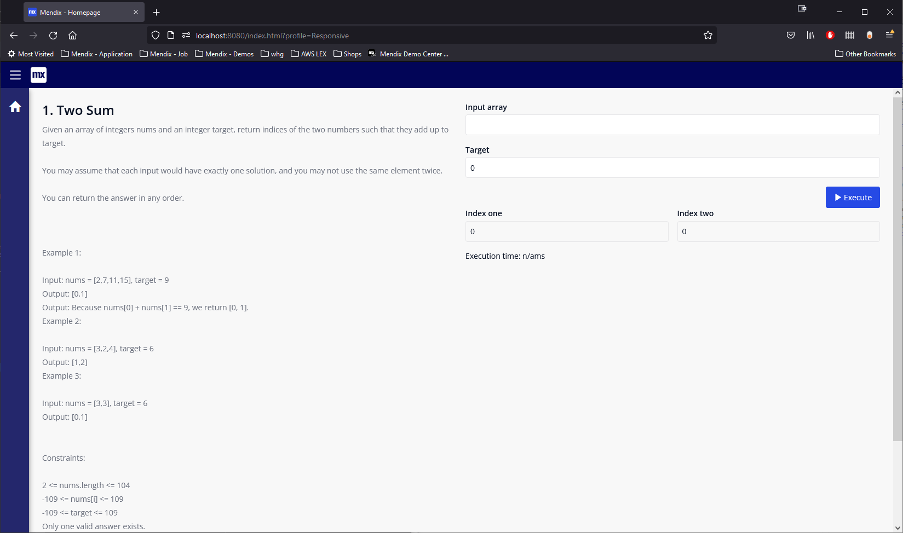
Once we’ve created this entity, we can put together a form to input the values and keep track of the details of the challenge. Nothing fancy – practical is the key here. As you can see, we also need to add a button to execute a Microflow. (A Microflow is what Mendix calls a function.)
Problem number one: The string array. Mendix isn’t really designed to work with string arrays. If you were tackling this problem in a real-world solution, you’d have a list of objects to work with. That feels a bit like cheating at this point so let’s just work with the string for now.
The Community Commons module, available on the Mendix Marketplace, provides a function we can use to split the string into a list, it also conveniently labels each item with an index. It won’t, however, convert the values into integers so we’ll just have to deal with that on the fly.
Now that we’ve got a list of values it’s just a matter of looping through list one and, assuming the first value doesn’t exceed the target, loop through again and see if there’s another value that will sum to form the target.
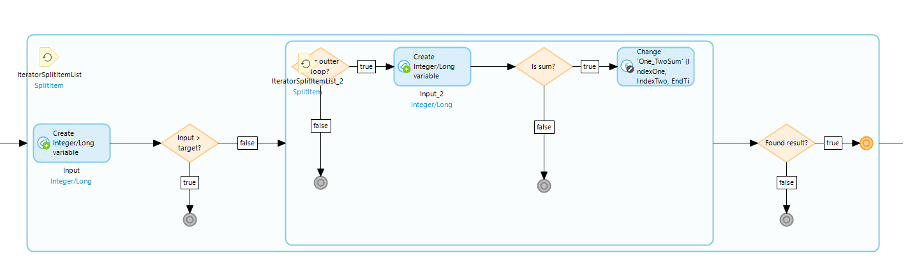
Setting it up this way should do the trick though, so let’s give it a go.
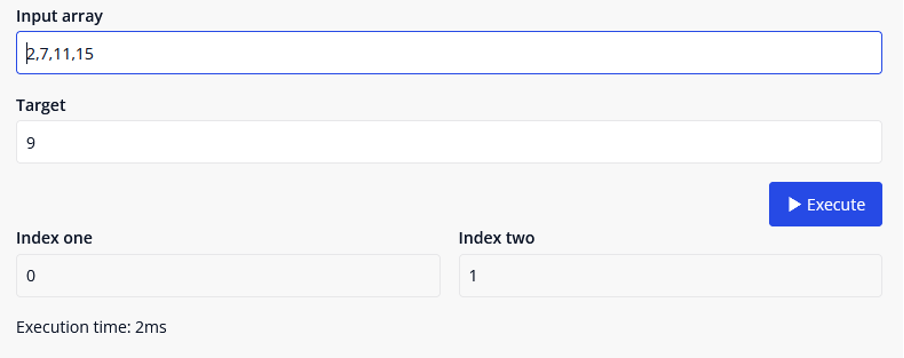
Perfect! Works like a charm. Job done, right? No. Not quite. There’s a further challenge: Can you come up with an algorithm that is less than O(n2) time complexity?
Given that there’s a nested loop in our solution, it is clearly not the most efficient way to do it. So, what is? Pointers. Sort the list and then put a pointer at the beginning and a pointer at the end. Check the sum of the two items and if it’s too low then move the first pointer up the list and if it’s too high move the last pointer down the list. Repeat until you find the solution or run out of list.
There’s going to be a few key challenges doing this. Firstly, the sorted list. Our list is stored as strings so sorting it by value isn’t going to work. We’ll have to loop through and convert each value to an integer.
Next you can’t access a list using index values with Mendix so we can’t just have two index pointers. There’s a simple work around though, using the list operation “Head” action to get the first object from the list. We can then just keep two copies of the list- one sorted ascending and one descending. As we work our way through the list, we just remove the item we’re currently checking from the corresponding list if it was too high or too low.
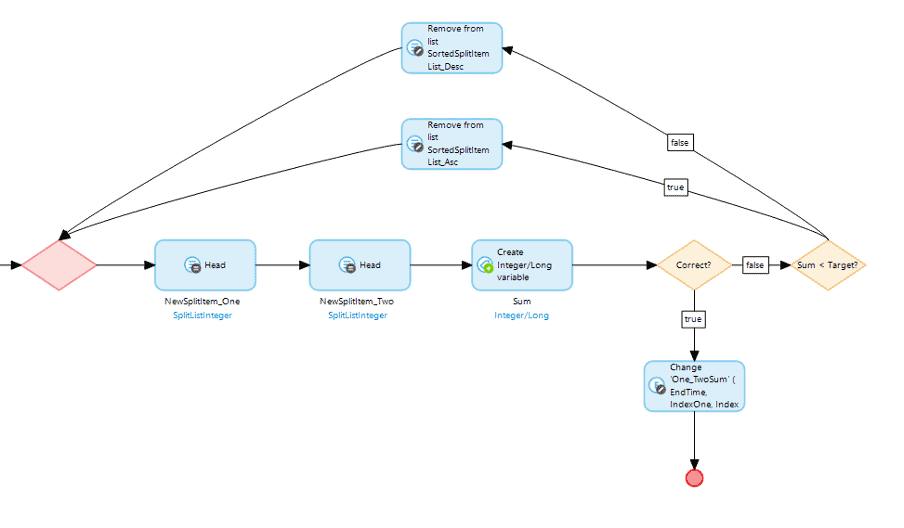
The application works as intended but is less efficient than the brute force approach of two loops for smaller lists of numbers. However, when the number of values is increased it does become much more efficient.
It just goes to show what you do in traditional code is possible in low-code with a bit of creative thinking. Now let’s take this a step further, what if this was a real-world business problem?
We’ll assume we’re working for a company that’s packing products and we want to pack them two to a box. We must match the weight limit of the box though – no higher or lower. To do this we need to find two products in our inventory that when packed together match our target value. Sound familiar?
First, let’s do this the Mendix way and load the data into a proper entity from the start. We’ll generate a list of random values and link that to the result entity we created earlier. We’ll also make it persistable so we can keep track of the products.
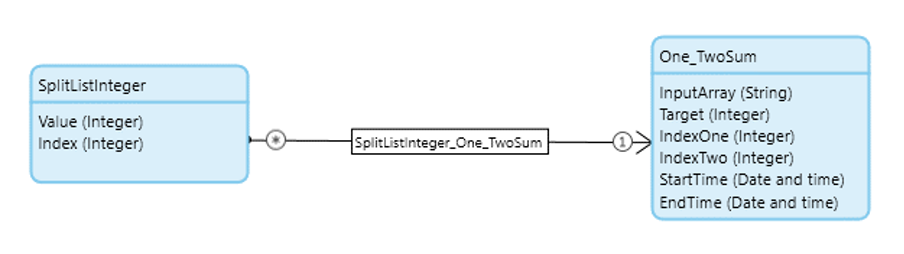
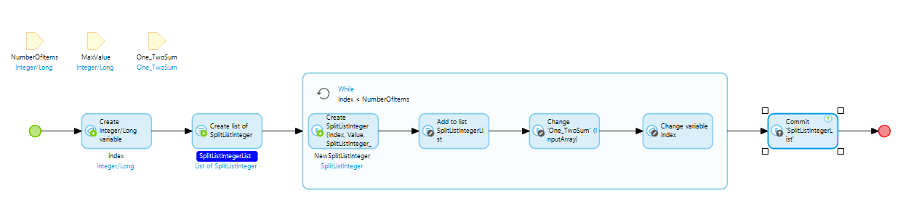
Now that we have a list to start with, we can just refactor the code we have from the second attempt. This section of our original Microflow can be easily extracted to a sub-Microflow and used in both our original function and the new function.
We now have three different ways of processing the data (when the list of numbers is generated, it populates the string array too, so the first two functions still work).
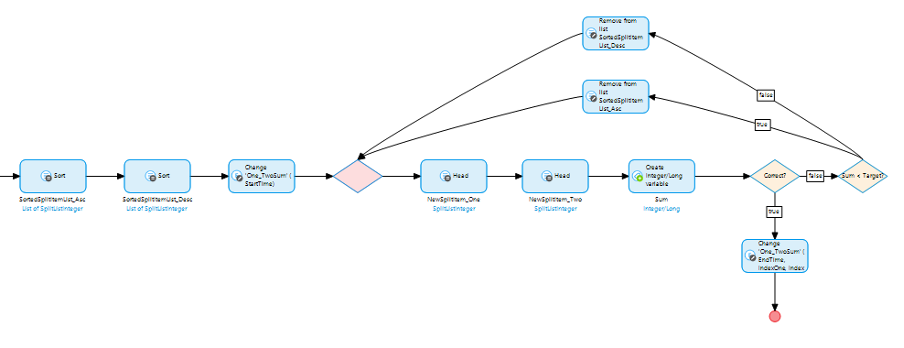
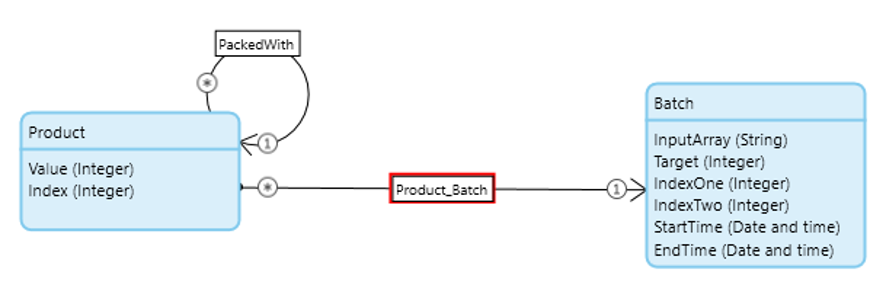
This will find us the first exact match. We’re going to need a way to track which products have been packed and which product they’re paired with. There’s plenty of ways we could do this but we’re going to use a self-association on the product; this way we can easily jump between products should we need to. I’ve also set the association between the entities to auto-delete any products if the main batch is deleted and you’ll notice I’ve renamed the entities, “Batch” and “Product” to try and keep things clear.
We’re also going to need to change the way the Microflow works to find matches because we’re not just looking for one exact match anymore. Now we want to find all the exact matches. We can also add a further optimization by putting the effort of sorting the list back onto the database.
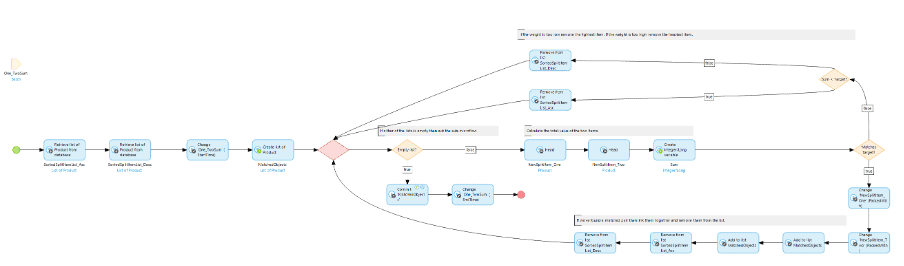
As you can see, when a match is found now it links the two products to each other and then removes them from the lists that are being checked. It then moves on to the next two products.
A screenshot of the finished application is below. We can see that in the batch shown we’ve managed to pair up 764 products. This isn’t the best way to show the data, as it effectively shows all the products twice because they’re shown from each side of the association, but it shows that it works!
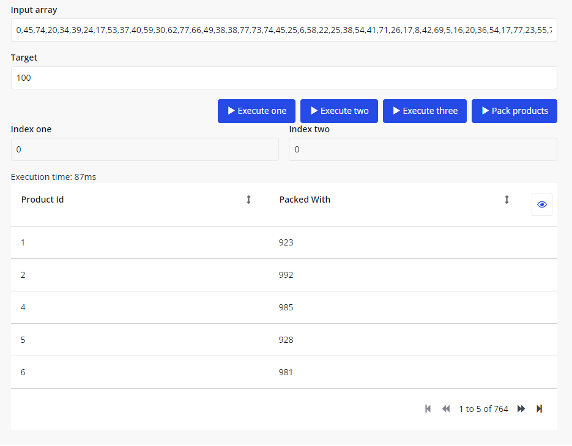
If anything, it highlights the fact that the best way to structure this data would probably be to have a third entity of “Box” and associate to the two products from there. You could then generate unique box IDs and only show each product once.
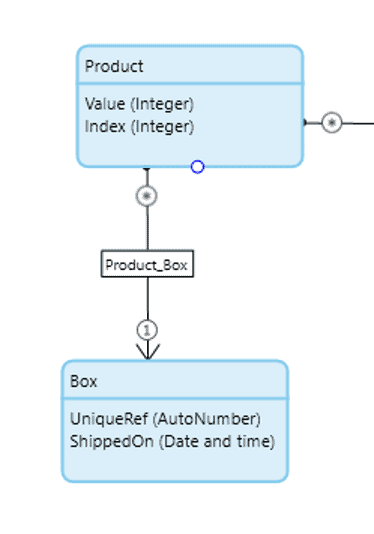
From there it’s only a few short steps to link this to customers, couriers and even a store front. Mendix can easily be used to build any of these applications – not just expense forms or holiday request systems. We might be a “low-code” platform, but that doesn’t mean you can’t use it to build applications that fix complex problems. And where low-code may not be enough, there’s always the ability to extend an application with Java actions.
Stay tuned for my next post where I have a go at one of the harder challenges: “Container with Most Water”, which involves taking an array of column heights and working out which pair of columns forms a container that can hold the most water or has the biggest rectangular area between them.