Data Querying & Management
Which Query Languages Does Mendix Support?
Mendix offers a number of ways to specify the data you want to retrieve:
- Mendix Studio Pro offers visual ways to specify your query needs via an expression editor
- To retrieve specific objects or a set of related objects, you can use XPath expressions
- For reporting needs where the aggregation and joining of multiple entities into a single result set is important, Mendix offers OQL queries
- A Java API is available if you want to use SQL queries on the application database
- For data sharing with other applications or data analytics tools, Mendix offers out-of-the-box support for OData on entities in your domain model
You can find more details in the sections below.
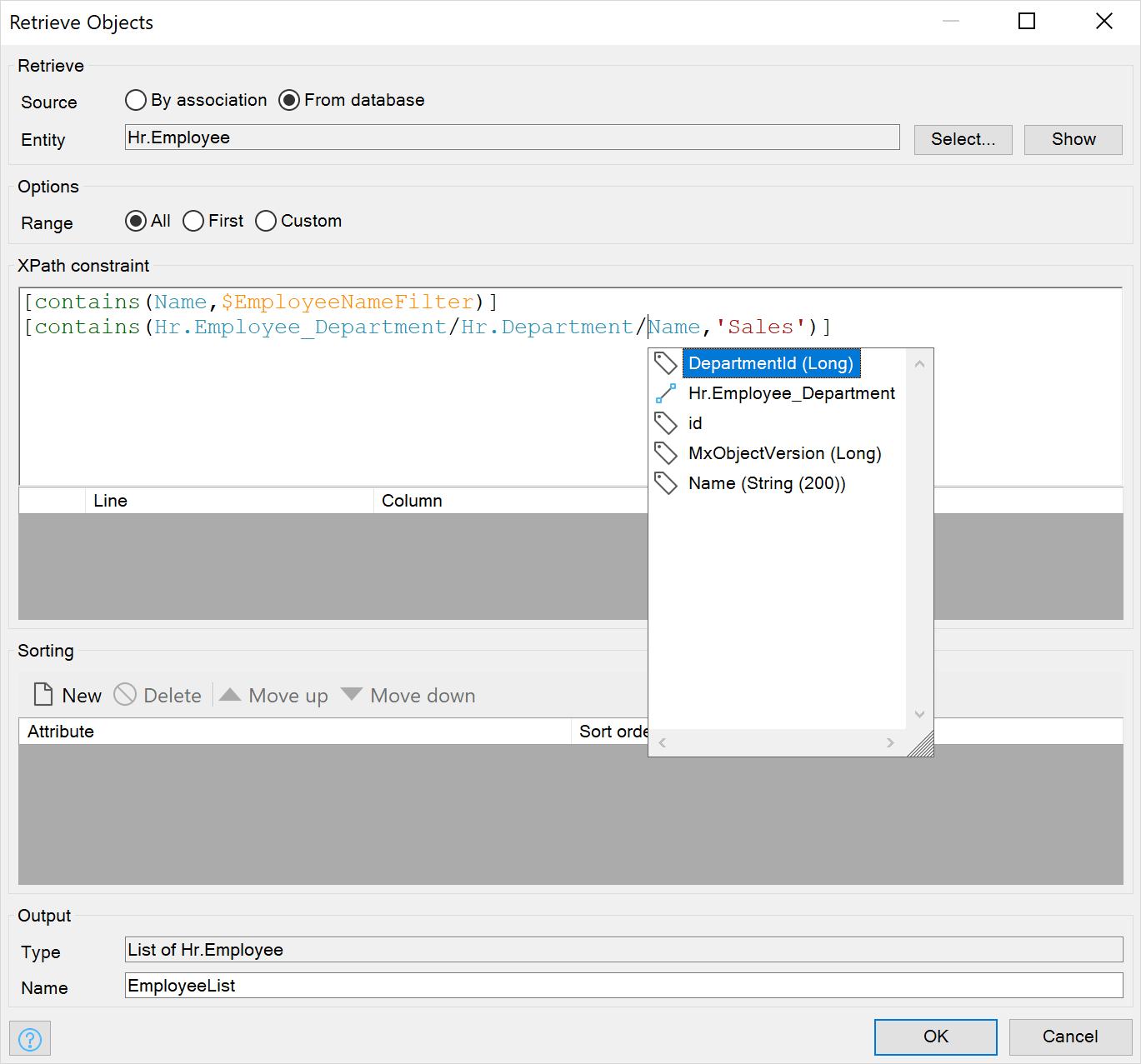
XPath
XPath is an easy-to-use query language that enables retrieving specific objects. You can use it to get objects that you want to display or edit in pages as well as to modify these objects through microflows.
With XPath, you can define expressions to filter the objects you are interested in, and you can use associations to retrieve and filter related objects. You can either write the xpath filters yourself to have full control, or you can use a visual xpath builder to simplify the process of creating an xpath filter.
XPath automatically ensures that all the access rules you define on your entities are applied.
For more details, consult XPath in the Mendix Studio Pro Guide.
OQL
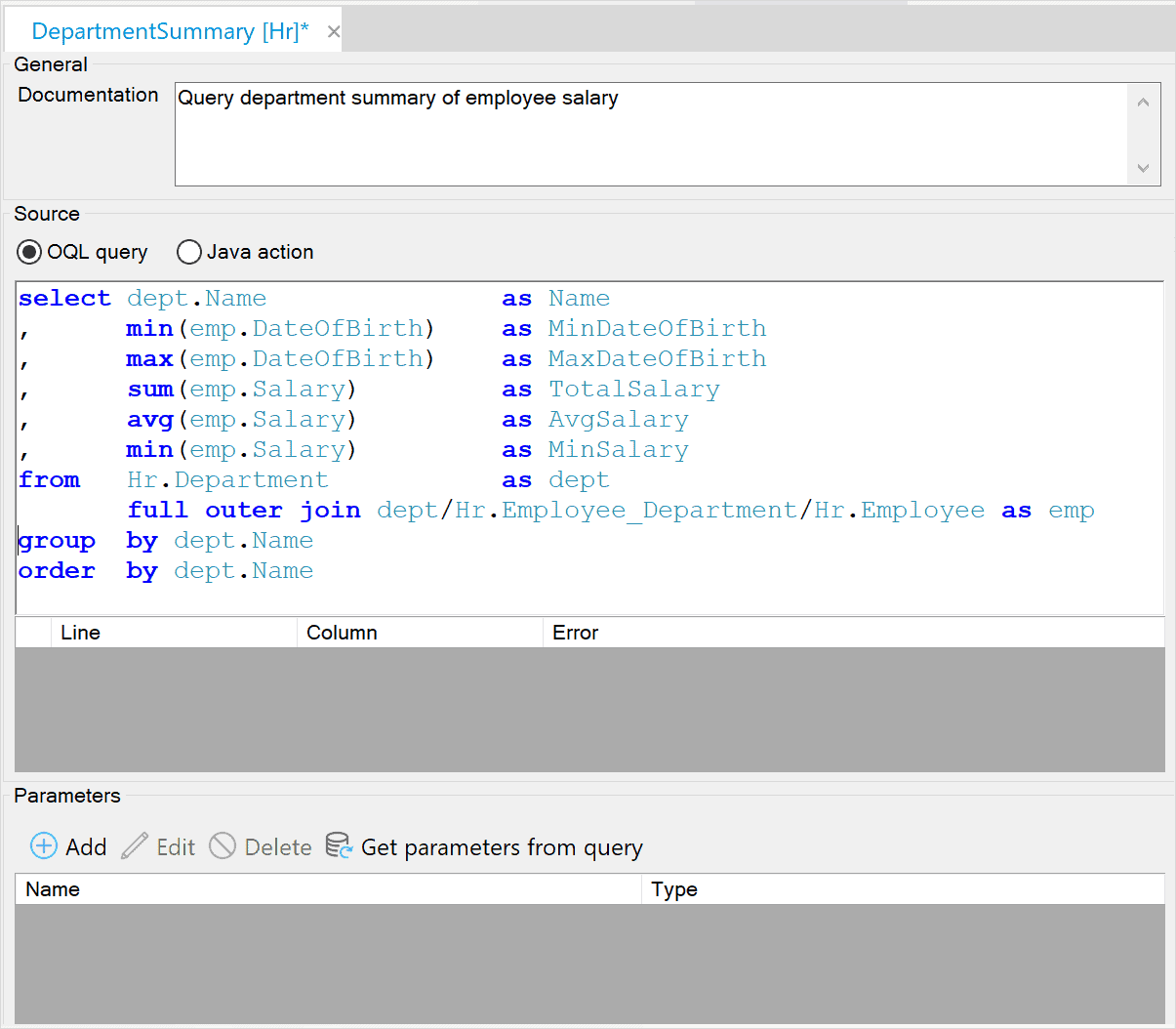
The Mendix Object Query Language (OQL) is a relational query language based on SQL. The major advantage of OQL over SQL is that OQL uses the entity and association names used in your model instead of the actual database table names.
View Entities are named OQL queries that can be used anywhere you can use a persistent entity. This means that it’s easy to use an OQL query as the source for a widget. All the default functionality of a widget, e.g., filtering, sorting and pagination in the case of a data grid, will be automatically applied on top of the OQL query that is used in your view entities. This makes it simple to use OQL queries as the source for your pages, charts, and APIs. OQL queries used in View Entities can be testing in Studio Pro to speed up development.
OQL can use the predefined relations (associations) to easily join objects without having to calculate which columns should be coupled. Despite these differences, many SQL keywords also work in OQL.
OQL can be used for reporting where you need aggregation functions while grouping over certain attributes. OQL is also used for more complex data preparation for pages and charts. OQL also helps decouple the APIs you publish, both Rest and OData Rest, from the underlying domain models. Another common use case for OQL is to define custom security expressions, which you need to define manually.
For more details, see OQL in the Mendix Studio Pro Guide.
SQL
All application data is stored in a relation database. In the Mendix Cloud, this is PostgreSQL, but there are other options as well, depending on your deployment environment.
Mendix provides Java APIs to directly interact with your underlying relation database. Through the Mendix Java API, you can use Java JDBC to run SQL queries and execute stored procedures. This provides you with a very powerful way of using your data, but it requires an understanding of relational database systems and SQL. You can use database vendor-specific extensions, but this will limit the portability of your application to other databases.
For more information on access to the JDBC API from Mendix, see DataStorage.executeWithConnection.
OData
OData provides a generic data access and query interface on top of the REST protocol. It enables a large range of third-party tools to access your data in a controlled way. These tools include basic query tools like LINQPad, spreadsheets like MS-Excel, and business intelligence and analytics tools like PowerBI and R. By providing access through OData, all the validation and security constraints defined on your data and handled by the Mendix Runtime are guaranteed to be applied. This means that OData is a safe and secure way to provide access to data to external parties.
OData APIs you define in Mendix can support both reading and updated data. The main REST operations, GET, PUT, POST, and DELETE are supported. You can provide custom logic to handle each of these to ensure correct validation of data before it is changed in the application database.
You can also expose View Entities as OData REST APIs, if you want to allow your users to access data through predefined queries. One big benefit of this is that you decouple your OData REST APIs from the underlying data model, so you can still evolve your database, and at the same time ensure stability of your OData APIs.
OData APIs can also expose microflow logic as OData Actions, in case you want your API users to access your data through predefined logic.

For more information on the use of OData with Mendix, see the Turn Data into Insight with Mendix OData Support and Using R to Gain Insight from the Data in Your Mendix Applications blog posts.
How Can I Optimize My Queries?
The Mendix Platform provides a lot of optimization out of the box. For example, when retrieving data for your pages through XPath, Mendix will automatically retrieve all the related information used on the page in one go. A concept called schemas is used for this. A schema tells the data retrieval component to not only retrieve a specific set of objects from the database, but to include specific associated entities in the result as well.
Besides optimized queries, Mendix also optimizes to avoid the need to query. This is done, for example, in the web client where objects are cached and reused through multiple pages. Another optimization made in the Mendix Runtime uses knowledge of the page structure to determine if objects need to be sent from the Runtime to the client at all.
If you need more control you can use View Entities and OQL queries to provide specific optimised queries. Since View Entities are a drop-in replacement for Persistent Entities in many situations, it’s easy to create a View Entity for a specific page or widget and replace a Persistent Entity with a View Entity. View Entities are especially useful when you need to extract data from multiple tables and you want to leverage the database optimiser to optimise these queries.
In addition to these out-of-the-box optimizations, there are a number of steps you can take to optimize your queries:
- Retrieve only what you need, and make sure you do not include attributes or objects in your query that you do not need
- Ensure that you have indexes on the following:
- Columns that are regularly searched or filtered on
- Columns that are used for sorting
In some cases—especially when you have a large number of objects—it can be helpful to use database-specific indexes. You can create these through the JDBC API, as described above in SQL.
How Can I Migrate Data from My Existing Database?
You may want to use existing data from old non-Mendix applications in your new Mendix application. If you need a one-time migration into your Mendix app, you have the options described below.
Database Replication Module
The Database Replication module available from the Mendix Marketplace enables connecting to a large number of different types of databases. It will show you what data structures exist in the existing database. You can then define (through a web page) what data you want migrated to your Mendix database. You can also define how you want to map the data from existing columns to your entity attributes.
Database Connector
The Database Connector module provides you with microflow activities to run queries on any database with JDBC support. This means you can create microflows to define what data you want from your existing database as well as how you want to convert that data into your new Mendix application.
Initializing Your App Database from an Existing Database
When deploying a Mendix application for the first time, you have the option to initialize it with data from an existing Mendix app. The main purpose of this functionality is to enable migrating from one environment to another (for example, from the Mendix Cloud to a private cloud). Once you have migrated your non-Mendix data into Mendix data, you can use this data to initialize a new Mendix app. This will work between databases from the same vendor, and also when moving from one database vendor to another. This means that you can initialize an Azure SQL database using data in a PostgreSQL database running on your workstation.
For more information, see How to Migrate Your Mendix Database and Backups in the Mendix Documentation.
How Can I Use My Existing SQL Database in Mendix?
You can use the External Database Connector to run SQL actions on any database you are using. To learn more about using an existing SQL database in Mendix, see the section How Does Mendix Support Direct Access to an External SQL Database? in External Data.
What APIs Does Mendix Offer to Extend Data Storage Behavior?
The Mendix Runtime provides Java APIs that enable extending the data storage behavior. Mendix ensures that anybody on your team can use these extensions by enabling you to provide them through normal microflow activities. For more info on this extensibility feature of Mendix, see the section What Kind of APIs Does Mendix Expose? in Openness (API & SDK).
Regarding data storage extensibility, the main Java APIs provide the following functionality:
- XPath – APIs to retrieve from the database using XPath queries
- OQL – APIs to retrieve data from the database using OQL queries
- SQL – APIs to directly use the underlying Java JDBC connection to run any SQL required on your application database
- Entity event handlers – APIs to register entity event listeners for all your entities, which can be used to extract auditing information or do a real-time export of all data changes to an external system
How Can I Control the Connection Pooling?
You can configure the number of concurrent database connections per runtime to the database using the custom setting ConnectionPoolingMaxActive.